Chaos Index for Simplified Pipelines and Analysis Gains
ChaosSearch minimizes data pipeline complexity and expense with its transformational architecture.
The ChaosSearch differences begin with a simplified data pipeline and minimal up-front data preparation work.
A data pipeline is how raw data from a source (an application, machine, etc.) travels over a network to a separate location such as storage or to a computer/application where it might be prepared (cleaned, transformed, etc.) before it is sent to a final destination like a database, where users can then search it for analysis and use.
A pipeline might appear to be a simple flow with stages that gather the data to a location like cloud storage, ingest/index the data to a location like a database, and then analyze the indexed data for use. However, the reality is usually never this simple.
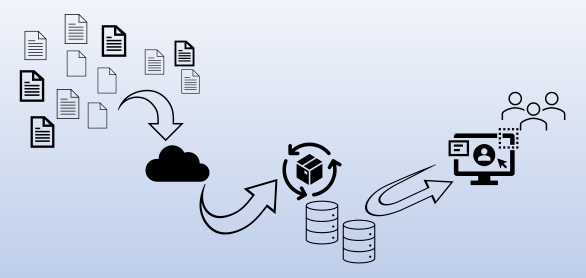
The Old Way
Most analytics solutions require costly data movement and preparation, with a little—or a lot—of up-front work:
- Data preparation are steps that pre-process raw data into a format that can be used by downstream tools. Data preparation happens early in the data journey and can include many discrete tasks like ingestion, data transformation, data cleansing, fusion, and data enrichment/augmentation before the prepared data is sent on to the destination.
- Data destinations are the stops in the data pipeline. Data might flow directly to one destination, or it could pass through several hops on its way to a final destination, adding time and management costs. Destinations can be locations such as monitoring, security, or observability services, or databases, data warehouses, or data lakes.
Data prep is often very process-intensive, especially for enterprises with data at scale. The need for data engineers to plan, define, and refine the schemas to enable querying can add time and costs to the project planning stages—this is often referred to as the toil of data preparation.
The ChaosSearch Way
ChaosSearch knows the challenges of the pipeline, and how those challenges often relate to the behavior and requirements of the databases and applications within the flow. With closer study of the advantages of cloud storage, and new designs for data representations, ChaosSearch found ways to simplify the complexity of and time spent within the data pipeline.
- The pipeline advantage: Cloud storage like Amazon S3 is designed to handle the volume, variety, and velocity of data at scale, cost-effectively, and with high reliability and availability. The patented ChaosSearch architecture leverages direct-to-cloud object storage for the most efficient pipelining of business and operational data.
- The schema advantage: ChaosSearch works to reduce—if not eliminate—the toil of data preparation at scale by combining our simplified pipeline advantage with our methodology for preparing data for analytical consumption. ChaosSearch resources called object groups connect seamlessly to cloud storage to read, filter, and index the raw data. Our Refinery ingestion quickly and automatically categorizes the raw source and fully indexes the data in near real time to create the patented Chaos format built for high performance and for flexible transformation post-ingestion.
- The destination advantage: The innovative ChaosSearch data lake platform takes full advantage of cloud storage to deliver an ideal data destination and optimized approach to governance. Data stays within customer storage at all times, under customer-owned access policies. Isolation keys within object groups can define separate and extensible silos (i.e., information partitions) of data at rest. Cloud storage inherently provides reliable, fast, and cost-effective storage as well as flexible controls for purging data when needed across silos. And, Chaos Index® creates a compressed representation of your cloud object data—providing 10-20x compression over the raw data or other indexing solutions.
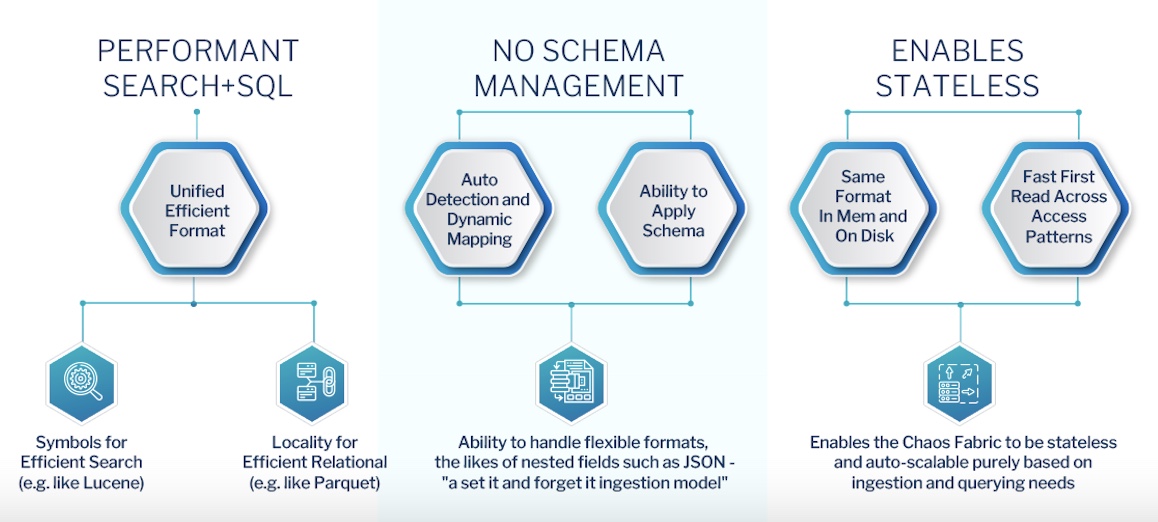
As data flows into cloud storage, ChaosSearch automatically indexes, quickly processing that data into its searchable index for analysis. Coupled with an intelligent query engine, ChaosSearch indexing allows fast “first reading” of cloud storage with no need for heavy caching or local storage in compute, resulting in a solution that is much more dynamic and greatly reduced in cost and complexity.
Updated about 1 year ago