Step 2. Define Object Groups
Create object groups to filter and select objects in your cloud storage buckets for indexing.
Cloud storage buckets contain a wide variety of objects. Unlike other solutions, ChaosSearch works directly with the range of content that users ship into their buckets, needing little to no time-consuming and costly ETL up front, and requiring no additional movement of the customer's data outside their control.
ChaosSearch is designed to read the content in the bucket that users want to index, and then create the versatile Chaos Index® data for analysis and monitoring.
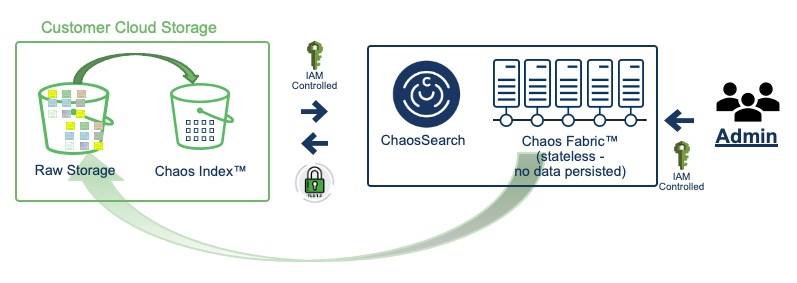
You use object groups to select the cloud-storage objects to index, apply the flexible rules for the content, and create the indexed data. You can select objects in one bucket by a specific pathname prefix location, and narrow the selection using a regular expression.
The steps to create an object group:
- Select the files that you want to index in the source cloud storage bucket.
- Specify filtering options and the indexing rules needed for the data.
- Select static indexing (for files already archived) or live indexing (for the new files streaming to storage, which uses a notification event service like Amazon SQS).
- Start indexing.
ChaosSearch provides flexible rules to control the indexing behaviors and the resulting schema and content. The end result is our next-generation, compact, lossless indexed data that supports highly performant querying with Elastic/SQL/ML.
Object groups can be created using the ChaosSearch console, APIs, or a Terraform Provider. The following steps show the console workflow.
Select Files to Index
To begin, click the Storage tab, then click Create Object Group. The Object Group Preview window appears:
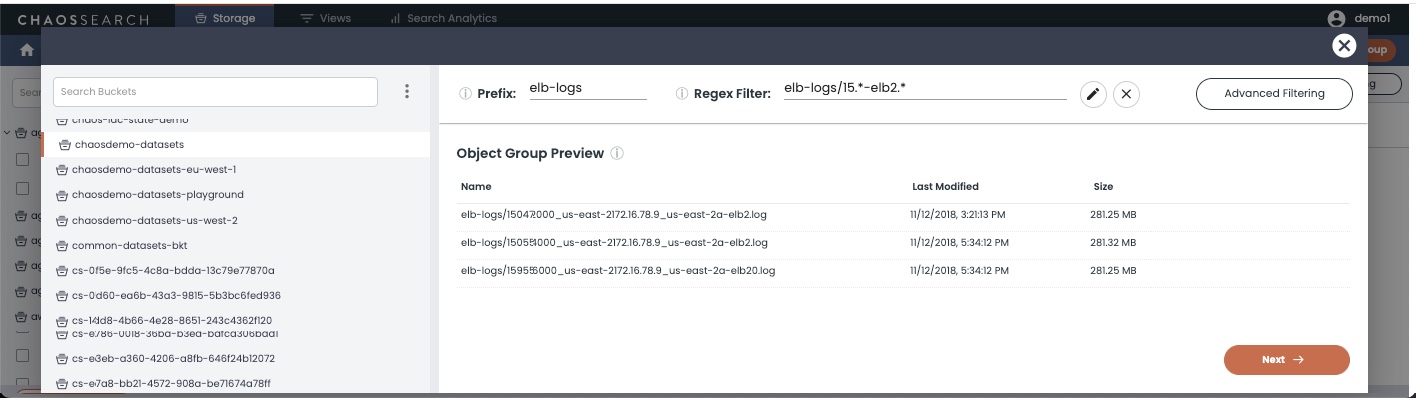
In the Object Group Preview window, a list of cloud storage buckets is on the left. Select the bucket that contains the files to index, and use the Prefix andRegex Filter options to narrow the list to the correct ones. The advanced filter controls have additional filtering options as well as the ability to configure data isolation.
After you have identified the files for the group, click Next to display a Content Preview window.
Review Content Preview Window
The Content Preview window summarizes the auto-discovered format of the included files (such as CSV, LOG, JSON, PARQUET, CUSTOM, or Unknown), the compression types (such as NONE, GZIP, SNAPPY, or SNAPPY-JAVA), and displays a preview sample of the content of the selected files. ChaosSearch can provide a content preview even if the files are compressed. This allows you to stay in the window while constructing regular expressions to parse the fields for indexing.
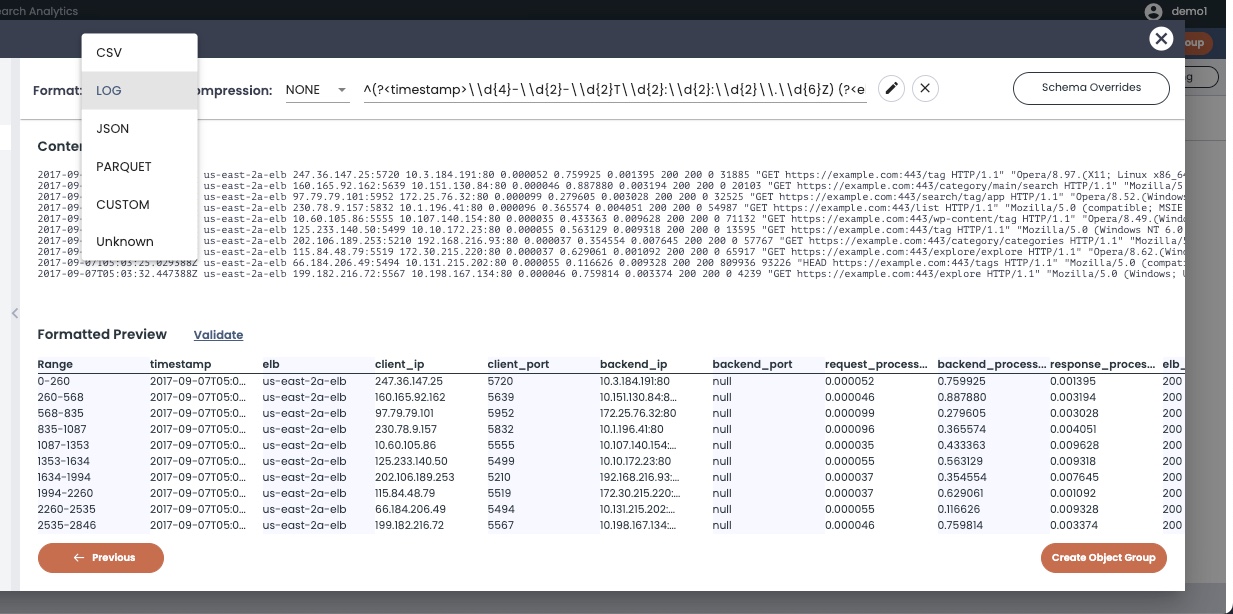
Depending on the format of the files you selected, the window displays other options such as delimiter values and a column heading field for CSV files, or array flattening options for JSON files. For log files, there is a Formatted Preview area (above) that shows a more user-friendly display of the field components of log files.
Click Schema Overrides to customize the schema of the files processed by the object group. You can override data types for one or more fields. You can also input a JSON file with rules and processing policies that tailor the resulting indexed data using field inclusion/exclusion rules, custom field naming, JSON Flex processing options, and similar schema-tuning controls.
Select Object Group Indexing Options
After you specify the field content and controls, click Create Object Group. The final step is to name the object group, and to specify some indexing options.
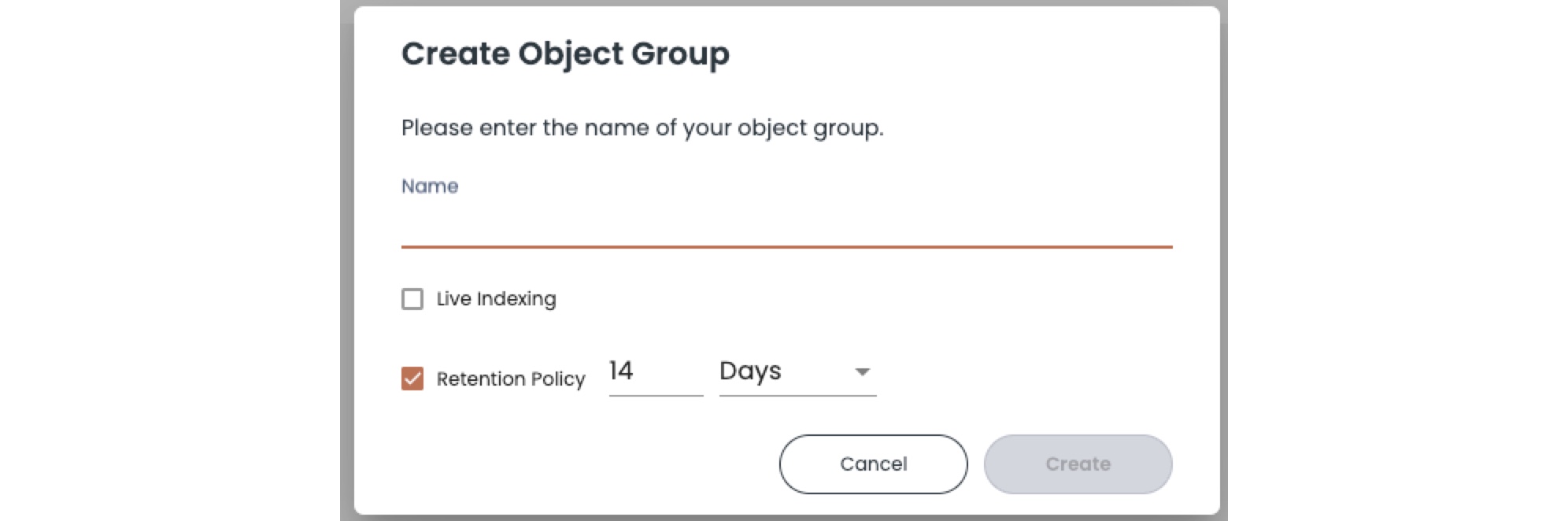
By default, an object group runs a one-time indexing for existing files already in cloud storage (called a static index). Select Live indexing to run automatic indexing when new matching files are written to cloud storage. Live Indexing requires a storage event notification service such as AWS SQS or Google Pub/Sub Project ID to send events when new files are written to storage.
For each object group, you can specify a retention policy that controls how long to keep indexed data before it ages out. The default is 14 days but you can select a time range for your analysis needs.
Start Indexing
After you create the group, the new group is added to the configuration, and the Storage > Properties page appears. Review the information for your new object group then click Start Indexing to index the files. Indexing performs a deep analysis of the files specified by the object group, and includes any instructions that you specified for schema overrides and filters in the resulting indexed data.
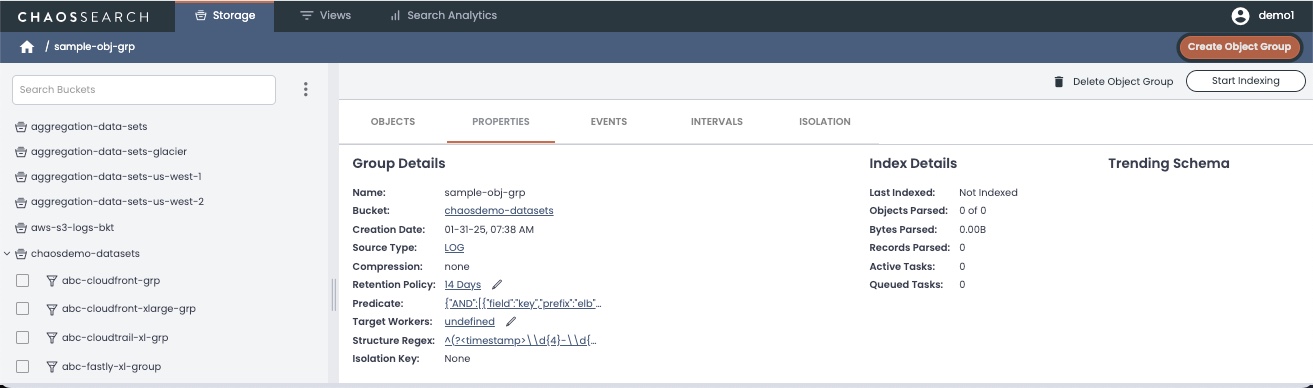
While indexing is running, the Properties tab updates to show more information about the index, and a pie chart summary of the data types for the discovered fields. When indexing is complete, the Start Indexing button changes to Restart Indexing.
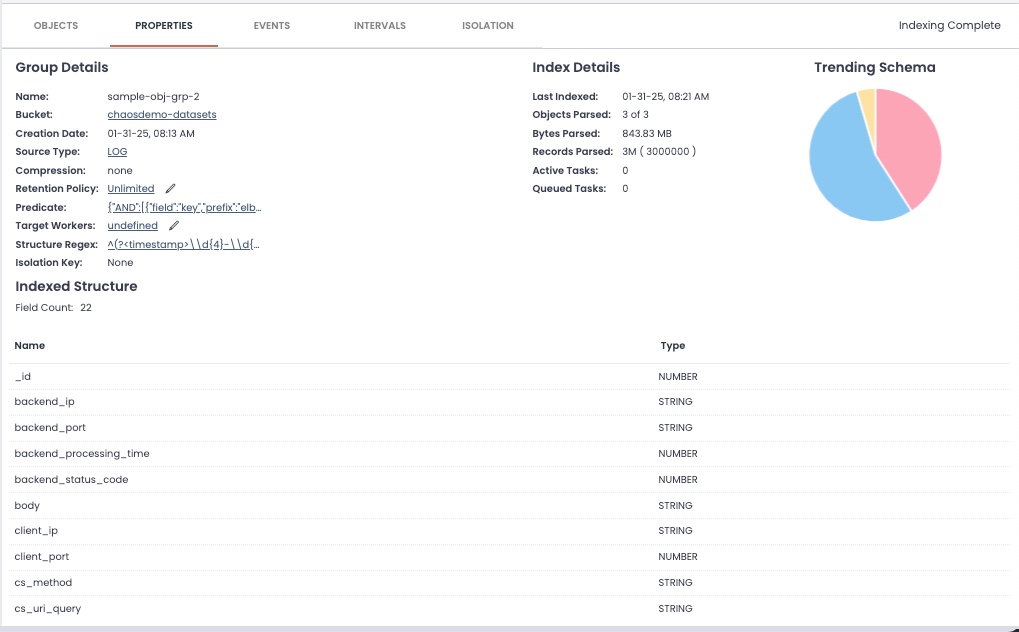
Review the Properties tab for a closer look at the fields within the indexed data. The Indexed Structure list shows each field in the indexed data, its name, and data type for a field.
On this page you can also review the following information:
- The Objects tab lists the cloud storage files indexed by the object group.
- The Events tab lists any indexing warnings or issues to address.
- The Intervals tab lists the daily Intervals of indexed data for the object group.
- The Isolation tab lists the optional isolation keys that might be used to separate the indexed data for the object group into tenants/organizations, applications, regions, or similar relationships within the pathname.
After you create and index an object group, the next step is to create a Refinery view to use the indexed data for visualization and analytics.
Updated about 1 year ago
What’s Next
Create Refinery views to enable users to visualize and query the indexed data for one or more object groups.