Searching JSON Views
Examples of OpenSearch Dashboards searches and visualizations using horizontally and vertically expanded JSON log files
Whether you use Search Analytics, SQL Analytics, or Elastic APIs to extract results for use with other applications, the Refinery® views help you to access the business and value insights in your JSON files. The controls for managing the flattening, storage, and filtering for JSON files gives your data analysts and BI consumers a high degree of control over the storage and visualization options.
This topic provides some examples of how visualizations might appear with horizontal and vertical expansion of a sample AWS CloudTrail log file.
Example 1: Horizontally Expanded CloudTrail Log
In this example, the CloudTrail log is filtered to an object group that uses horizontal expansion. The Refinery view for the group does not use JSON Array Transformation to perform any virtual vertical transformations of the Records column.
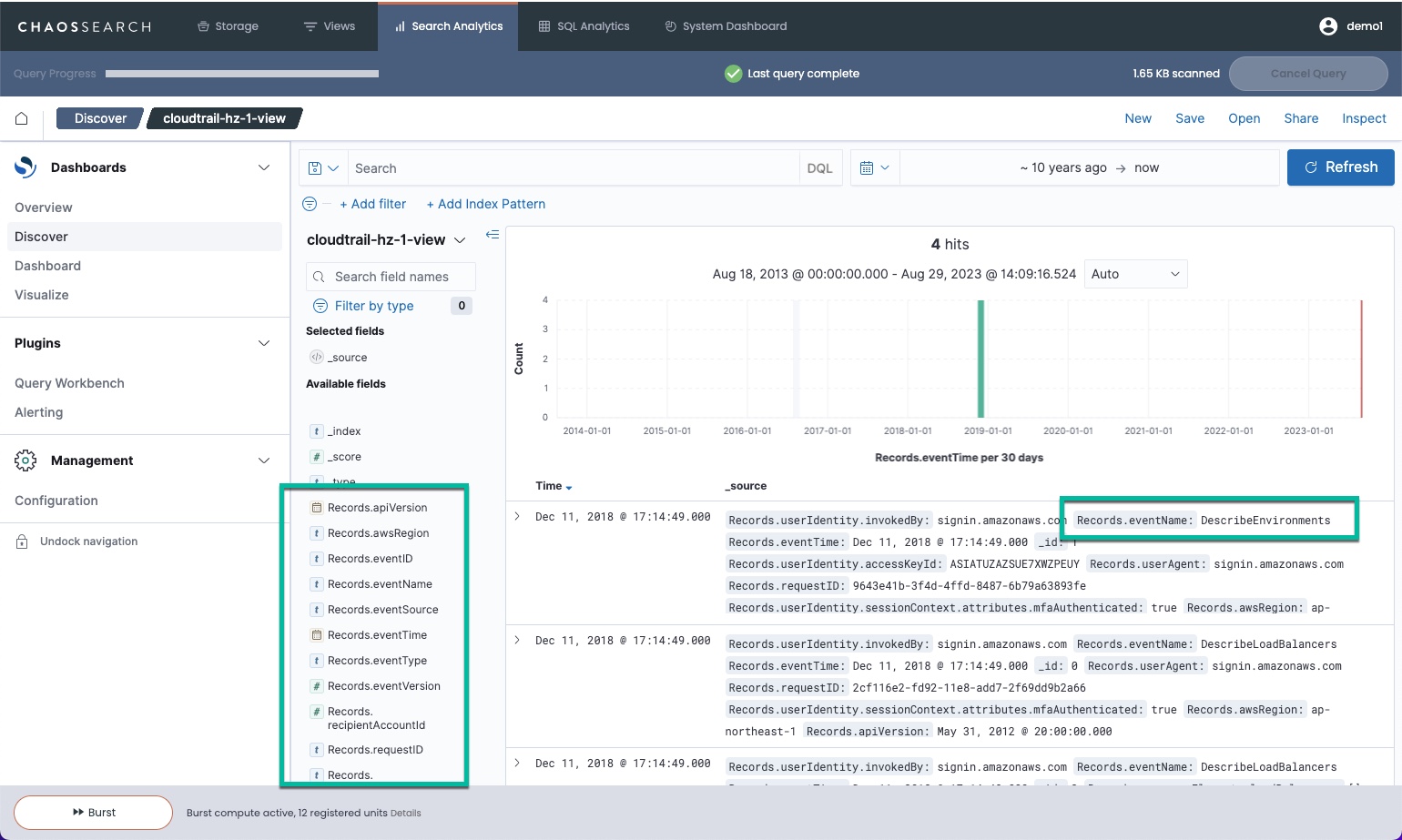
For this configuration, the Discover report for the CloudTrail log data shows one record where all JSON properties are flattened to separate columns. The Discover output shows the first column sequence for Records.0.* (Records.1 through 4 have the same structure.)
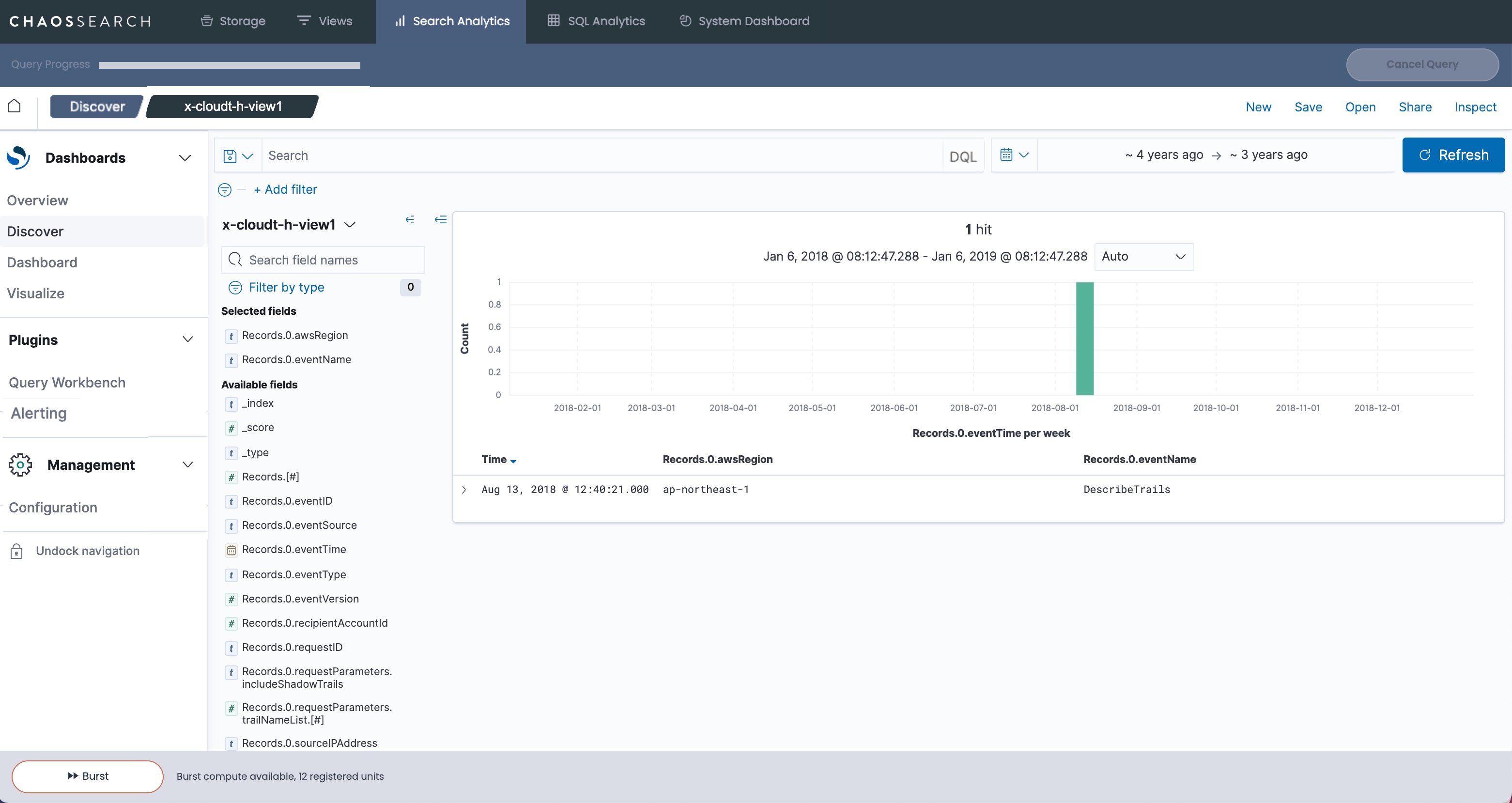
A horizontal index can help to maximize compression, but some possible visualizations are limited. You can use simple filters to search for specific values, but it is not possible to show aggregate analysis. For example, if you wanted to create a pie chart to show the number of different eventName records in this log sample, the horizontal flattening does not support the ability to split the bucket by eventName. The available Terms to choose from are specific to each attribute column (Records.0.eventName), as in the following example:
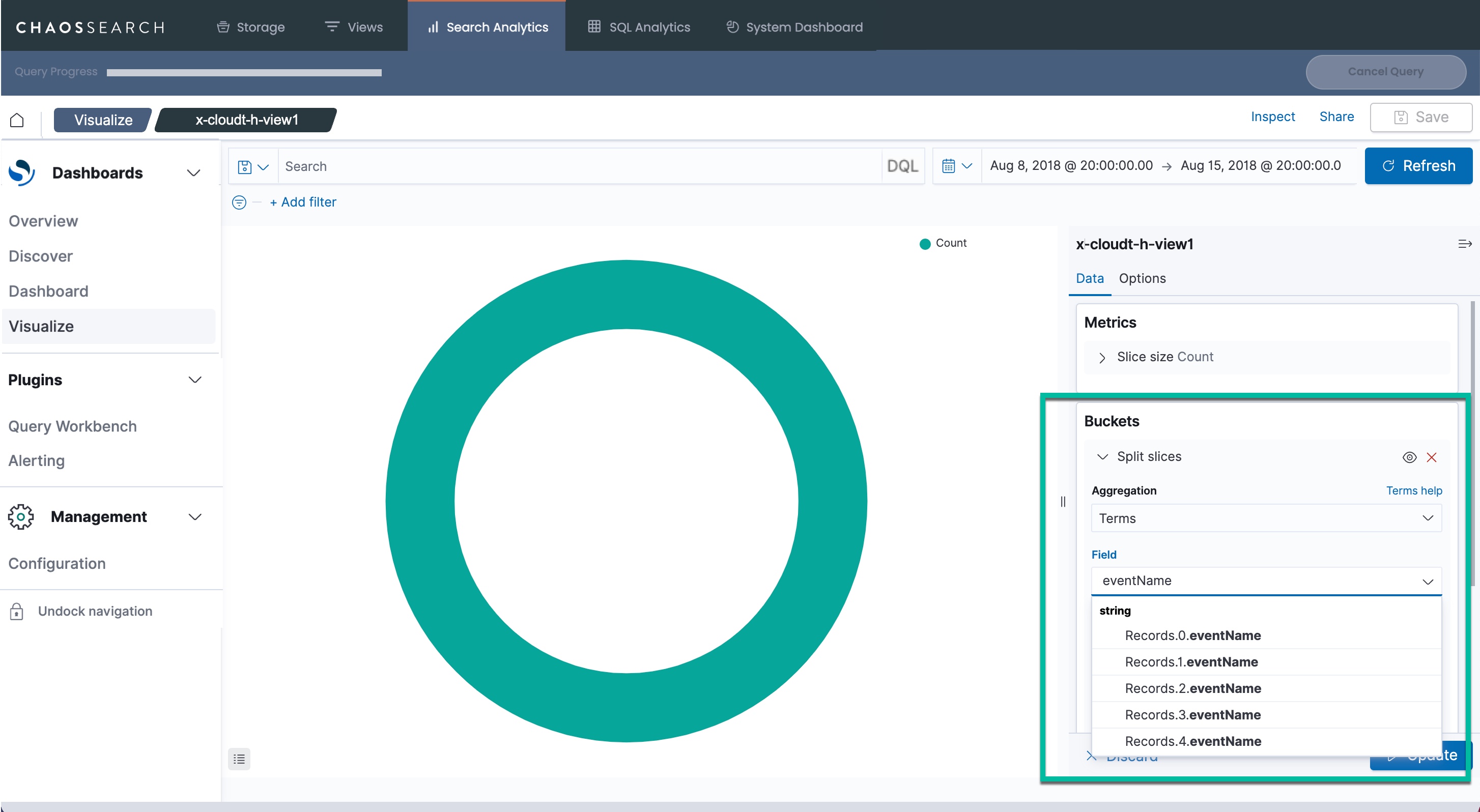
For horizontal expansion, the options for querying and visualization are basically string matches to find content within a record, or visualization of a single column value like Record.0.eventName.
Example 2: Vertically Flattened CloudTrail Log
In this example, the CloudTrail log is filtered to an object group that uses vertical expansion. For this configuration, the Discover report shows 5 records in the CloudTrail log sample. The Records array members are flattened to rows for each array member:
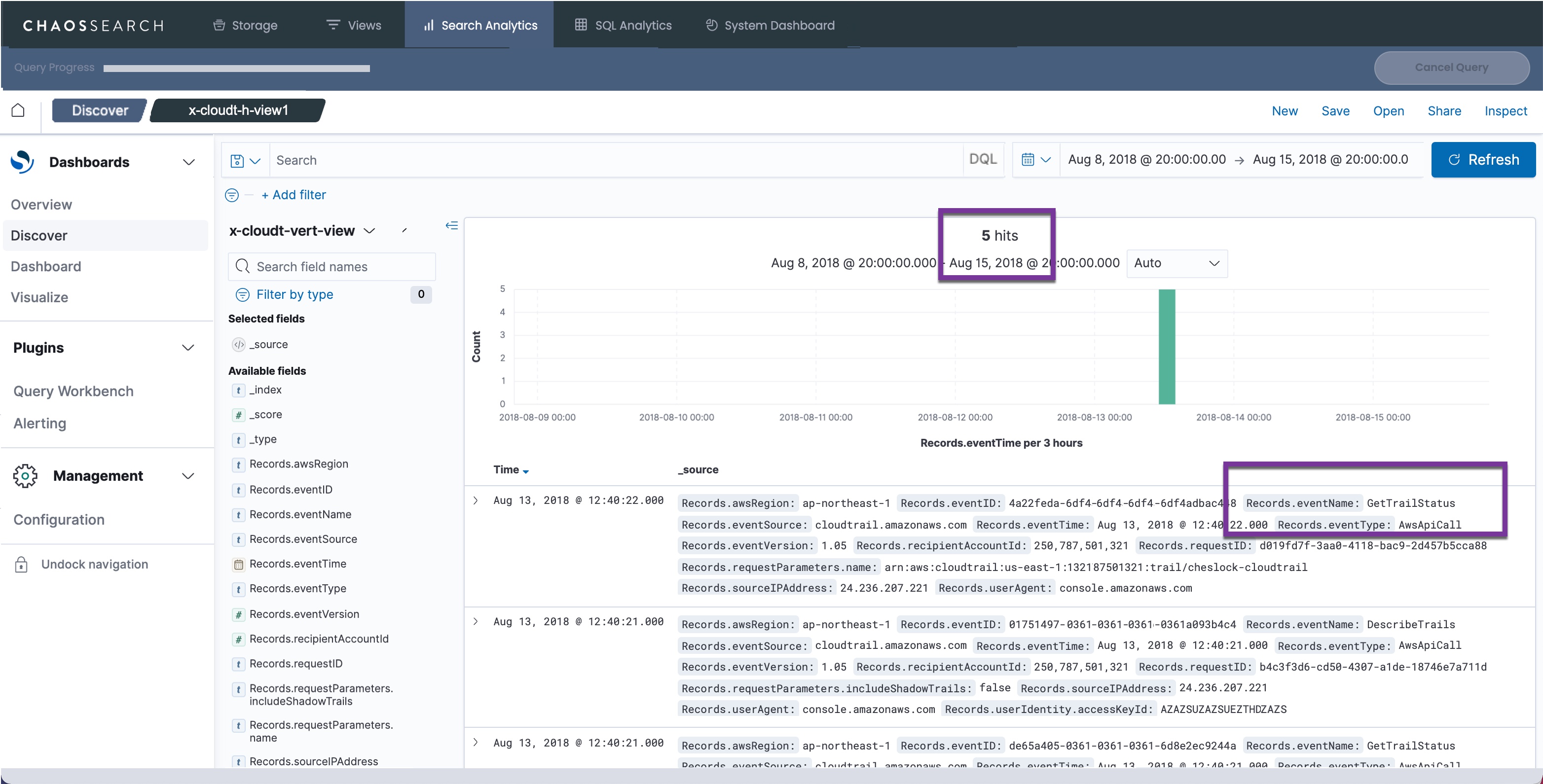
With vertical flattening, the granularity of the data allows for more analysis options. For example, to create a chart of the records and show a distribution by CloudTrail eventName, you can split the pie chart by the Records.eventName attribute:
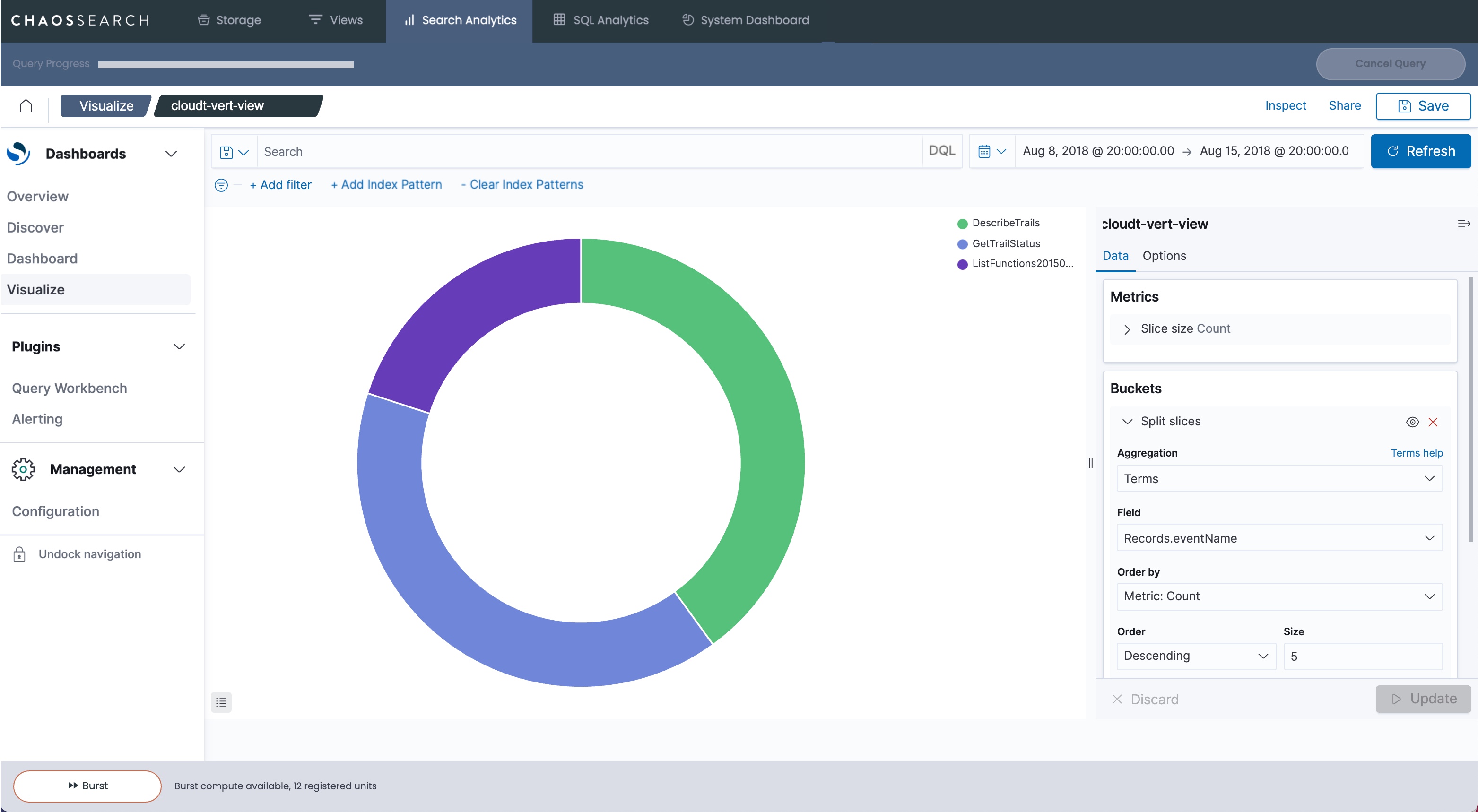
Example 3: JSON Array Transformations for Vertical Analysis and Horizontal Storage Benefits
The advantage of JSON Flex is that you have layers of flexibility in the options for the setup of your object groups and views. You can choose horizontal expansion for object groups to efficiently store the indexed data. Within the view definition, you can choose a virtual vertical expansion for fields to materialize the columns for the view using the JSON Array Transformation window.
A sample window follows where the CloudTrail Records attribute is configured for a virtual Vertical expansion in the view definition:

With this set of options, the materialized Record columns for the view are similar to how they would be if they had been vertically expanded in the object group's index fields. The Record columns can be used for filtering and aggregations, even though the indexed data is stored in its horizontal expansion.
For this example, the virtual vertically expanded Records properties are selectable for graph filtering:
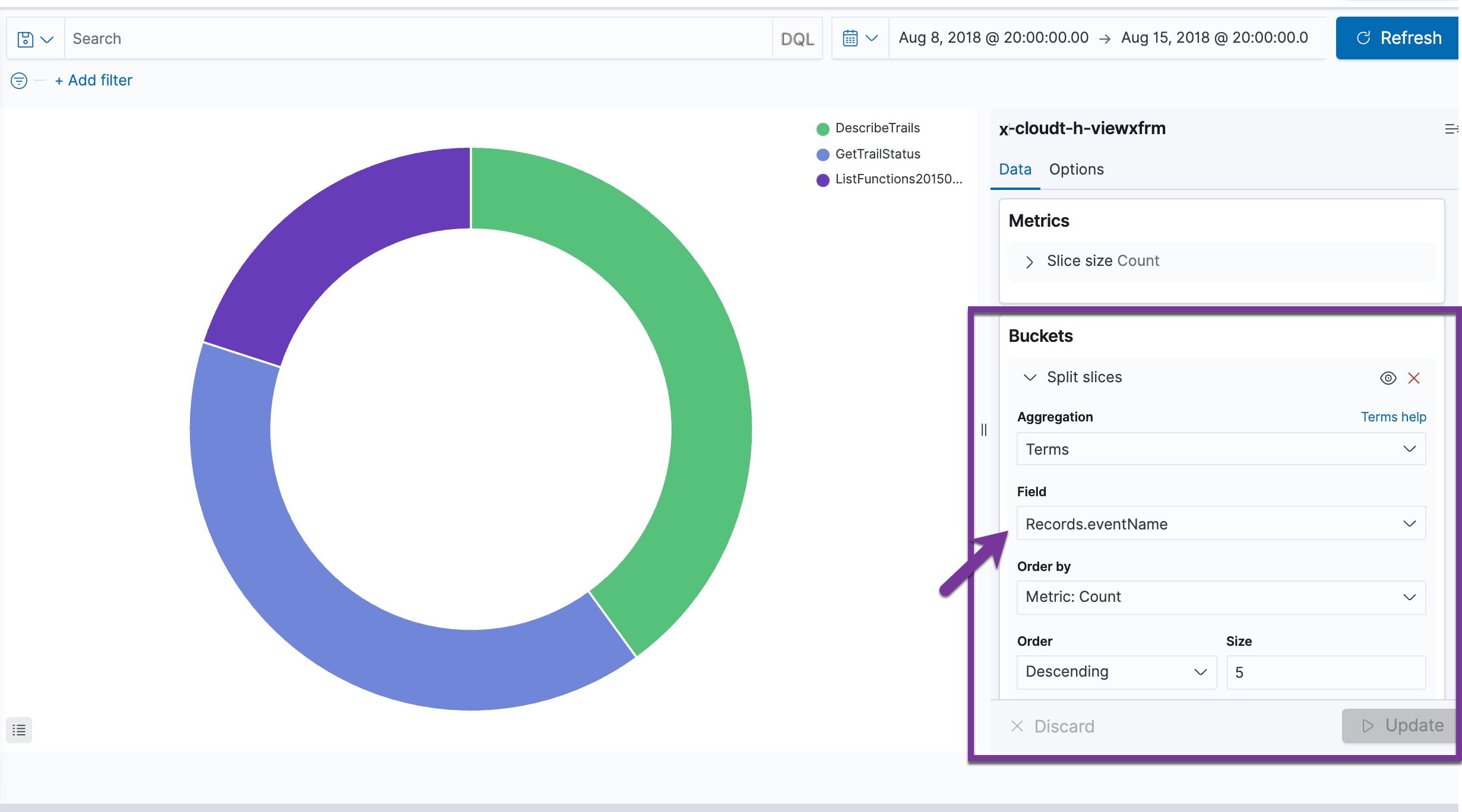
With the JSON array transformation feature, you can take advantage of more granular JSON properties for filtering to improve the usability for user analytics.
Example 4: Array Flattening Depth and JSON String Values
If you create an object group and select an Array Flatten Depth value other than Unlimited, some of the JSON array content will be indexed as a native JSON string value. As an example, using the same CloudTrail log file, if you create an object group of either expansion method and you specify an Array Flatten Depth of None, the resulting nested Records object is flattened into a Records column that contains all the native JSON structure concatenated as a string, for example:
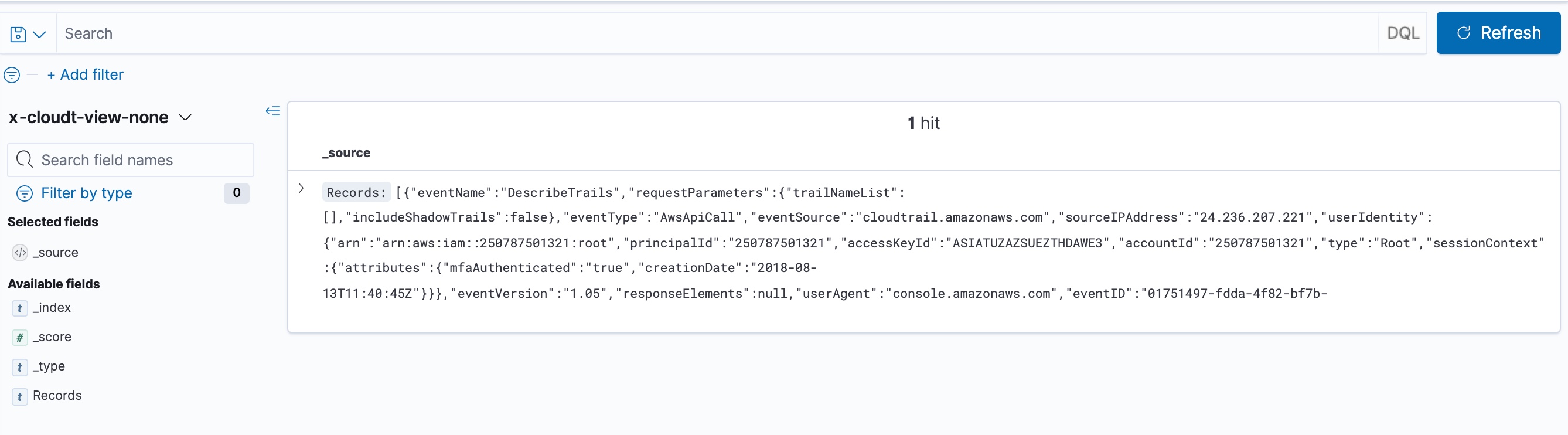
This type of native JSON content can be searched for string values. Normally, the JSON properties in the string would not be accessible as filter or aggregation columns. However, using the ChaosSearch Materialize with JSON view transformation option, you can define JSON properties within the string to materialize as columns in the view. See Schema Transformations for more information about this feature.
Example 5: Searching Inside Nested JSON
When JSON string columns are transformed with Treat as Nested JSON, users can search the content using Elastic nested query syntax.
To search within a nested field in DQL, the filter query must:
- Begin with the name of the column that contains the nested JSON string.
- Use curly braces to navigate within nesting levels, and to traverse within sub-nested fields.
- Use "." notation to specify fields within objects.
- Escape special characters with a backslash like
\\,]\?,\^,\$and so forth.
As an example, the following screen shows a Discover search for CloudTrail log files where the Records.requestParameters field is indexed as a JSON string. Within the view, the field is transformed using Treat as Nested JSON, and in Discover search, it is possible to use nested query syntax to search for content inside the properties and levels of the string, for example:
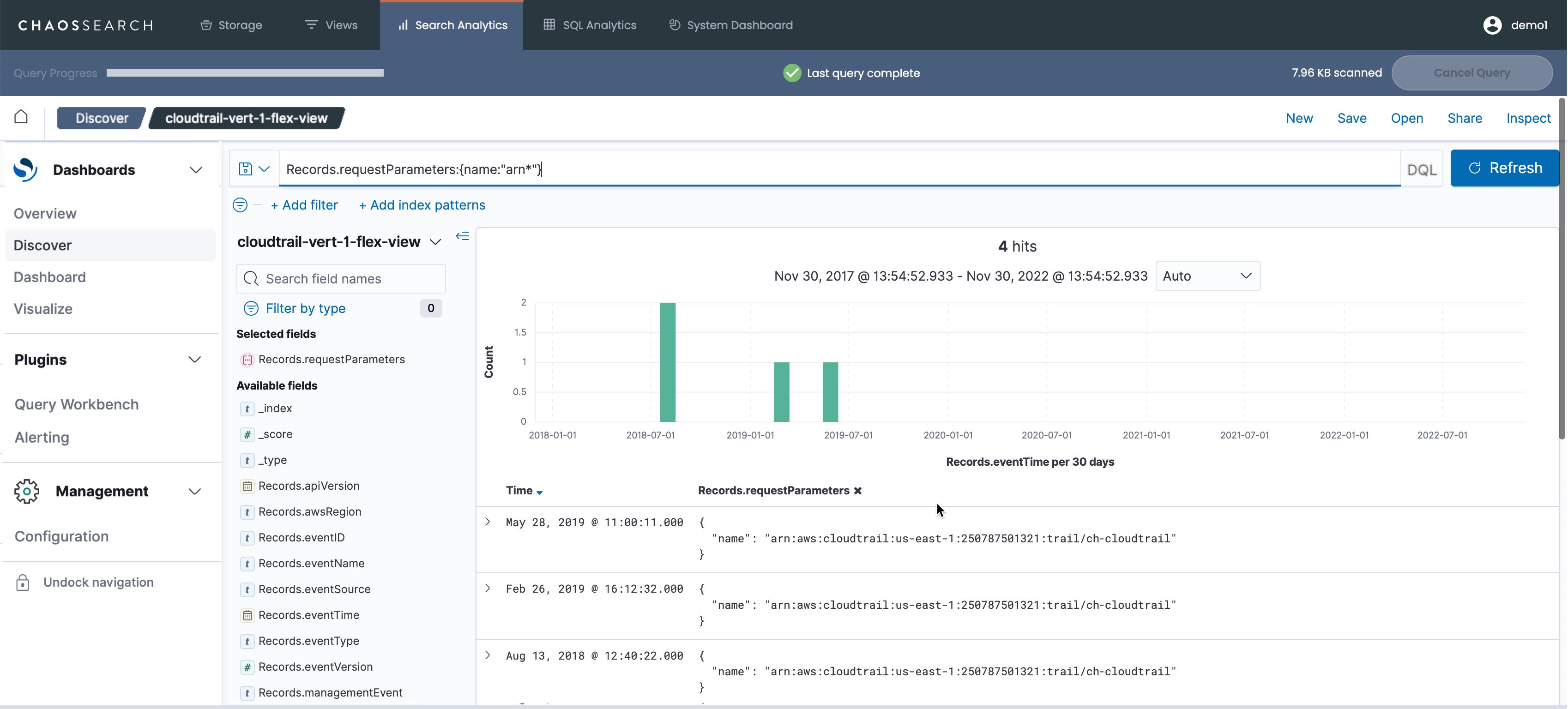
As another example, the following excerpt from a sample CloudTrail log file shows nested objects and arrays in the content:
{"Records": [{
"eventVersion": "1.0",
"userIdentity": {
"type": "IAMUser",
"userName": "Alice"
},
"eventTime": "2014-03-06T21:01:59Z",
"eventSource": "ec2.amazonaws.com",
"eventName": "StopInstances",
"awsRegion": "us-east-2",
"requestParameters": {
"instancesSet": {
"items": [
{
"instanceId": "i-ebeaf9e2",
"geo": "us"
}
]},
"force": false
},
...In this example, assume that the Records.userIdentity and Records.requestParameters fields are indexed as a JSON string similar to this:
{"instancesSet": {"items": [{"instanceId": "i-ebeaf9e2","geo":"us"}]}, "force": false}Example: Matching a Single Field
A sample nested query string for searching for a force value of true would be:
Records.requestParameters:{force:"true"}Example: Matching a Single Field inside a Nested Array
Whenever the query must traverse into an array inside a nested field, specify curly braces {} to indicate a further level of nesting. For example, a sample nested query string for searching for a geo value of eu would be:
Records.requestParameters:{instancesSet.items{geo:"eu"}}Example: Matching Multiple Fields inside a Nested Array
To search in multiple fields inside a single object inside a nested array, include the target fields and query parameters inside the nested array curly braces. For example, a sample nested query string for searching for an instance ID of i-abcd1234 and geo value that is not us would be:
Records.requestParameters:{instancesSet.items{instanceId:"1-abcd1234" and not geo:"us"}}
Treat as Nested JSON fields can be used with chart aggregations.View columns that are transformed using Treat as Nested JSON are available in Search Analytics charts as nested fields that can be selected for metric or bucket aggregations. See Creating Visualizations for more information about nested JSON fields and JSON Path support.
Updated about 1 year ago