Object Group Isolation Keys
Isolation keys separate the indexed data for an object group for analysis filtering and compute efficiency.
Isolation keys are an optional configuration setting. When you define an object group to index data, you can define isolation rules to separate the indexed data into different segments of the daily interval as the data is written into storage.
Isolation is a filtering mechanism to keep information that is specific to one area (such as a customer, team, location, etc.) separated from the information specific to other distinct areas. The isolation keys uniquely identify the data associated with each isolated segment and can be used as a filter options to specify which subset(s) of data to include in views used for searches/queries or visualizations.
Isolation also helps to improve worker/compute efficiency for live indexing object groups. Each live indexing object group is assigned a minimal reserve of dedicated worker resources to watch for new file notifications and to index new files. If you create three live object groups to index three different areas of files, three of those minimal reserves are allocated. If one live indexing object group can do the work to index all three sets of objects (files must be in the same bucket, have the same format, compression, and index processing rules), that one minimal reserve of resources is used much more efficiently, and more workers are available to support other object groups or tasks like queries.
The following image shows a basic representation of different types of log files saved in a customer's raw cloud-storage location. With isolation keys, one object group could index the different collections of LOG objects.
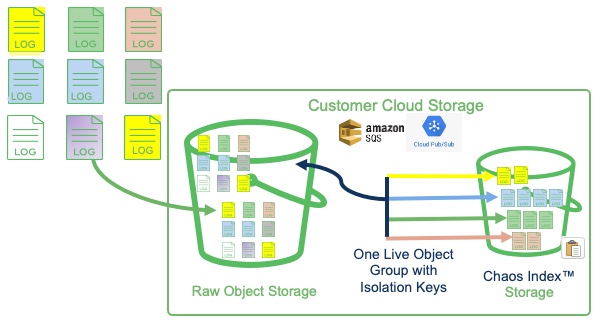
The resulting indexed data is stored in separate segments that contain only the data for an associated isolation key.
How Isolation Keys Work
In the same way that object groups use regular expressions to filter the storage objects and find the objects to index, ChaosSearch uses a regular expression to define the isolation key rules for separating the matching storage files and their resulting indexed data. As a simple example, if your cloud storage has web site authentication log files stored in S3 using the following pathname format:
app/backup/<site>/auth-records-<date>.log.gz
You could create isolation keys to separate the indexed data for each <site> using a regular expression, for example:
app/backup/(\S+?)/auth-records*.log.gz
Well-Defined Bucket Organization
An important requirement of isolation is a well-organized cloud storage bucket. Each object group can index files stored within only one cloud storage bucket. For isolation regular expressions, the files for the different areas must land in the same cloud storage bucket; must be the same in terms of format, compression, and indexing rules; and must use a common, repeatable, pathname format similar to the <site> pathname example above.
An advantage of a common pathname format is that additions to the areas can be picked up automatically. For example, if a new site is added, or an existing site is deprecated, the regular expression rules can detect and handle those changes without intervention. A deprecated area will no longer have files to index, while a new area will result in a new isolation key, and new separate segments of data for that area going forward.
The following topics provide an overview of how to identify when object group configurations can benefit from isolation keys, and how to configure object groups to use isolation keys.
After you create object groups with isolation key rules, you create Refinery views that show the data for one or more isolation key slices, as described in Creating a View for Isolated Data. End users of that view can query or visualize the data for the associated isolation key(s), without seeing the data for any other isolation keys.
Updated about 1 year ago