Schema Policies
Learn how to use ChaosSearch schema policies to include, exclude, and customize the fields in an object group's indexed data.
ChaosSearch offers schema policies that control how ChaosSearch will process the content of the files ingested by an object group. These policies are a series of one or more field selection rules that help to more efficiently process the incoming files ingested by the object group, automatically applying rules to include only certain fields, to exclude fields, and to apply rules to specific types of content like JSON structured arrays and nested objects.
The following table lists the schema policy types. More information is available later in the topic.
| Schema Policy | Purpose |
|---|---|
| Whitelist/Blacklist Options | Options that control which fields in the source files to include or exclude from the object group and the generated indexed data for those source files. |
| JSON Array Options | For JSON files that have nested arrays, there are indexing options to vertically expand an array of interest for indexing and analytics, or to specify an array and its properties that you want to store as a JSON string. |
| JSON Nested Object Options | For JSON files with nested objects, you can select one or more nested fields and its properties that you want to index as a JSON string. |
JSON field selection fileThe Schema Policy user interface requires you to create and import a JSON file with the settings for the field selections and processing rules. That JSON file must be stored in a file location accessible from your work system so that you can import it from the browser.
Applying a Schema Policy Filter File
Once you have created a rules JSON file, follow these steps to use the rule during object group creation.
To specify the schema policy rules file for an object group:
- While you are creating the object group, and when you're in the Content Preview window, click Schema Overrides in the top right corner.
- In the Schema Overrides window, go to the Schema Policy area at the bottom.
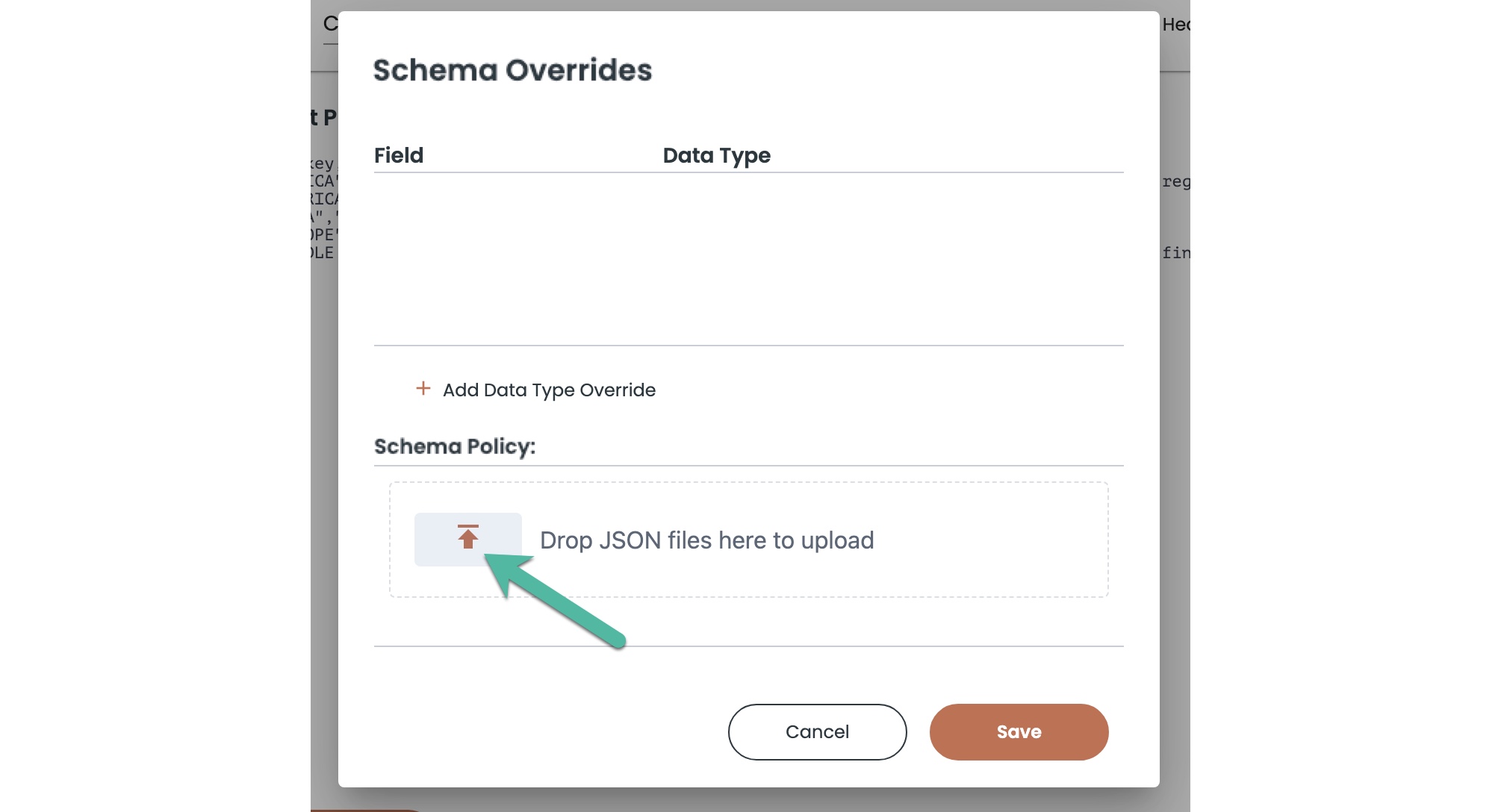
- Click the Drop JSON files here to upload link to open a file browser, and select the JSON file that contains your custom schema policy rules. Alternatively, you could drag and drop the JSON file into the area from a file explorer window.
- Click Save to add the policy to the object group. You are returned to the Content Preview window to continue with object group creation.
Verify the JSON schema policy file before you load it.After you prepare the JSON file with the field selection policies that you want to use, make sure that you verify that you have a properly configured JSON file. It can be helpful to validate the file using a third-party or public JSON validator before you load it.
If you load the file, click Save, and the window appears to hang, the problem is usually a formatting error in the JSON file. Verify the file, fix the format errors, reload the updated file, and save again to return to the Content Preview window and finish creating the object group.
ChaosSearch applies the schema policy to the resulting fields in the Chaos indexed data schema. You must index the object group to see the effect of your policy and rules on the resulting fields. It can be helpful to index a small set of files as a test and review the object group's Properties information to confirm that the policies are taking effect as expected.
Field Inclusion and Exclusion Policies
As a default behavior, ChaosSearch indexes all of the fields in source log and event files that match the object group content filters. Sometimes log and event files contain fields that are not meaningful for analytics or queries. Rather than index information that is not valuable, it is a good practice to skip unnecessary fields.
Use field inclusion/exclusion to manage the object group indexed fields without the toil of transforming raw files.While it is a common practice to remove undesired content in the log creation phase (before files are written to cloud storage), that content cleanup is not always possible or easy. Changing the log content can be complex, require iterations, and could become a repetitive task. Fields deemed unnecessary for one form of analysis might be useful for another, adding duplication and rework to get the right content into the logs.
The ChaosSearch field inclusion and exclusion rules are an on-the-fly way to filter the source files that you want to index in an object group to only the content that is needed, reducing or eliminating the need for costly rework of the source files. The resulting ChaosSearch indexed data for the group is more tailored and compact, leading to better query performance and end-user information experience.
The field selection whitelist and blacklist policies define the rules for including or excluding fields that exist within the source log files.
If most of the source file fields are useful for indexing and analysis, you could use a blacklist policy to exclude only the specific undesired fields from the indexed data. The blacklist can contain one or more fields, and the index process will skip (not index) those fields. Similarly, if the source log and event files have only a subset of fields that are valuable for analysis and queries, you could use a whitelist to index only those fields and omit all others in the indexed data for that object group.
A sample blacklist definition contains statements similar to the following. In this example, the referenced fields (field_name and field_name2) of the source files will not be included as fields in the indexed data. All other fields will be included/indexed. The field names that you specify must match the field names in the source object file exactly.
{
"type": "blacklist",
"excludes": [ "field_name", "field_name2", ... ]
}A whitelist definition for specifying a list of fields to include/index contains statements similar to the following. Only the fields that exactly match the whitelist (field_name and field_name2) will be included in the object group and indexed data. All other fields in the source log and event files will be omitted from the object group index.
{
"type": "whitelist",
"includes": [ "field_name", "field_name2", … ]
}You could also use a regular expression pattern set to include or exclude fields that match the specified patterns. For example, to include only the fields that match the specified patterns, you could create an inclusion file like the following:
{
"include": true,
"patterns": [
"^line\\.level$",
"^attrs.version$",
"^host$",
"badfield",
"field*"
],
"type": "regex"
}If you change "include": true to "include": false in the previous example, you create a regular expression blacklist that will omit any fields that match the specified patterns from the object group index.
There is no limit to the number of fields that you can include or exclude, up to the overall service limits to the number of fields in an object group.
For JSON field names, make sure that you capture the full JSON nested field path, which might require a property.prop1[.prop2...] dotted-notation pathname for a deeply nested field. It can be helpful to create a test object group for a small sample file to correctly identify the field names in a sample resulting object group to ensure that you have the correct field names.
JSON Array Options
For JSON files with arrays, you can use the JSON Flex options to specify how to index the arrays and their elements. For example, you can use horizontal or vertical expansion, and you can specify an array level (that is, how many nested levels) of elements to index as separate fields. See JSON Flex Options Reference for more information about JSON files and the available ChaosSearch optimizations for JSON file indexing.
When JSON files have arrays, you can use the vertical_selection_policy to specify expansion rules for one or more arrays. The vertical_selection_policy options support includes/whitelist and excludes/blacklist syntax to specify whether arrays are or are not vertically expanded for analytics and filtering controls within searches and visualizations. This policy is helpful in cases when you selected horizontal expansion as the default for an object group, but you want to vertically expand selected array for indexing. Similarly, you might have a vertical expansion object group but only to a specific level (e.g., 1), but that you want to whitelist an array for expansion below that expansion level.
A sample JSON vertical_selection_policy definition follows, where an array called app_status will be vertically expanded during indexing:
{"vertical_selection_policy":[{"includes":["app-status"],"type":"whitelist"}]}For JSON files that are indexed vertically or when you use thevertical_selection_policy to make nested arrays fully indexed and available for analytics and filter controls, you can use the array_selection_policy to specify one or more arrays to ignore for vertical expansion; that is, the specified array and its entire contents will be stored as a JSON string in the indexed field. The JSON string content is searchable for analytics and querying.
A sample array_selection_policy follows, where the Records.requestParameters array will be indexed as a JSON string, not as individual fields and rows.
{"array_selection_policy":[{"excludes":["Records.requestParameters"],"type":"blacklist"}]}As a combination example, there might be cases where you want to use horizontal flattening in general, but vertical expansion for a specific array, and then JSON string indexing for a specific nested subproperty of a vertically-expanded array. With JSON Flex, you can layer the options for this indexing behavior. The following example vertically expands the Records array and the Records.requestParameters.eventInfo array, and indexes the specific nested arrays Records.requestParameters.HistoricalMetrics and Records.responseElements.MetricResults as JSON strings.
{
"vertical_selection_policy": [
{
"includes": [
"Records",
"Records.requestParameters.eventInfo"
],
"type": "whitelist"
}
],
"array_selection_policy": [
{
"excludes": [
"Records.requestParameters.HistoricalMetrics",
"Records.responseElements.MetricResults"
],
"type": "blacklist"
}
]
}JSON Nested Object Options
Nested objects are indexed as separate properties, which could result in a large number of separate fields in the indexed data. Some nested objects and properties might be better suited and more efficient to index as JSON string blobs rather than as separate property fields.
The field_selection_policy allows you to specify the names of nested JSON objects that you want to index as a JSON string blob instead of separate properties. The contents of that nested object and any nested properties below it are indexed as one contiguous JSON string field. The JSON string content will be text searchable like any string field, with the benefit of a reduced number of indexed data fields in the object group.
The field_selection_policy options support an include/regex and excludes/blacklist syntax to specify the nested objects. You can use include with a regex to use regular expressions for matching the nested fields to process as a JSON string. You can also use a blacklist to specify the nested field names to index as JSON strings.
Sample field selection policy definitions follow. The first example uses regex patterns to specify the fields to treat as JSON strings. Examples for a blacklist rule or a combination of both forms are on separate tabs.
"field_selection_policy": [
{
"include": false,
"patterns": [
"^field[.]prop[.][A-Fa-f0-9]{64}.*",
"^property[.][A-Fa-f0-9]{64}.*"
],
"type": "regex"
}
] "field_selection_policy": [
{
"excludes": [
"plan.jobs",
"unusable_job_outputs"
],
"type": "blacklist"
}
]{
"field_selection_policy": [
{
"include": false,
"patterns": [
"Records[.]userI.*[.]sessionContext[.]attr.*",
"Records[.]req.*"
],
"type": "regex"
},
{
"excludes": [
"Records.additionalEventData"
],
"type": "blacklist"
}
]
}
Materialize Options for JSON StringsThe JSON fields and properties that are converted to JSON string blobs normally cannot be used for analytics as filters or metrics for aggregations, however ChaosSearch offers a Refinery view technique to materialize a property inside a JSON blob for analytics use.
When you create the Refinery view, you can use the Materialize with JSON transform to specify an embedded JSON property by its JSON path, and the property will become available for analytics and filtering as a post-analytics, materialized column. Similarly, you could use the Materialize with JQ transform to use a
jqfilter expression to create a materialized column from content inside a JSON string blob.
Updated about 1 year ago