Creating Object Groups
Object groups organize and associate similar objects in your cloud storage for ChaosSearch indexing.
In the object group definition, you specify the source files to index using patterns based on their pathname/location and file names in the storage buckets. Patterns could be very broad (index all files in a location), or very specific (index only the files that match specific patterns), possibly using a regular expression. The patterns and filters have various options and can vary based on the file types and how those files are organized in the storage buckets.
A bucket organization plan is a good practice.There are great benefits to implementing a well organized structure for storage buckets and objects. While there is no one-size-fits-all model for organizing objects, using good practices like an extensible pathname style, intuitive bucket and folder names, consistent object naming, tagging, and so forth can help to ease the filtering of objects and tasks like setting isolation key rules.
When selecting the files to include in an object group, note these important considerations:
- An object group can index files located in one bucket; files from multiple source buckets are not supported.
- An object group expects only one file format (e.g., LOG, CSV, JSON, Parquet, custom).
- An object group expects only one compression setting (e.g., GZIP, Snappy, or none).
It is good to start with a few object groups to index a few very specific types of cloud-storage files for indexing. As a best practice, work with your ChaosSearch Customer Success team to plan the rollout of object groups to index your data. ChaosSearch has a very simple object group creation process, with options to support many common types of log and event data.
The following video offers a short overview for creating object groups. Continue reading for detailed steps on the process and the various options.
Create an Object Group
To create an object group:
- Log in to the ChaosSearch console and click Storage.
- In the left list, select the bucket that contains files that you want to index. (If you don't select one now, you can do so in a later step.)
- Click Create Object Group in the top right corner.
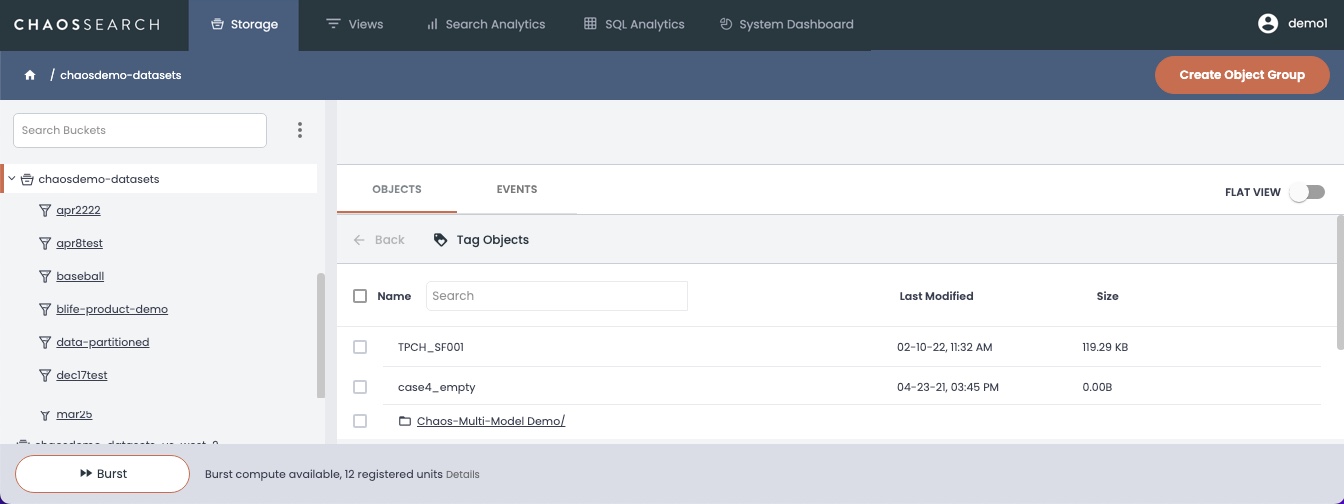
The Object Group Preview window appears.

-
In the left list, if you already selected a bucket, the Object Group Preview area on the right displays folders and files in your selected bucket. (If you have not yet selected a bucket, select your source bucket to see the list of folders and files.)
-
Identify the files to include in your object group for indexing using a combination of the following methods:
- Prefix – Type a folder name or pathname to navigate to the location of the source object files to index. The Prefix helps to quickly drill down to the location of the source files in well-organized buckets where files are typically collected in unique but related paths. For example, if a bucket organizes log and event files using a structure like
<application>/<team>/<region>/<date>/<*.log>where each path could vary, the Prefix can find the files specific to an account, likeWebApp/sales/eu/01-15-2025/and so on. See AWS prefix guidance for more information about specifying prefixes. - Regex Filter – Type a regular expression that matches on object file names to include in the group. While
.*matches all files found in the Prefix location, you can more narrowly select files using the information in their paths likeWebApp/sales/eu/.*/.*.json.gzto find the JSON zipped files. See Java documentation for more information about specifying regular expressions; make sure that the regular expression is sufficient to match on an entire object file pathname.
Objects listing could take some time.When an object group has a very sparse regex that matches very few S3 objects, the Objects listing could take a long time to find and display matching objects included in the group. In some cases, the Objects listing UI could display
No Matches.
Regular Expression TipsWhen you are constructing a regex, it is best to construct the most specific regex values possible to find your cloud storage files of interest for the object group. If possible, avoid using wide (greedy) wildcards in the beginning or middle folder pathnames because a wildcard such as
.*early in the path could result in unnecessary traversals of folders where no matches will be found. For example, consider the following bucket pathname structure:Bucket structure:
test/acct-1/app1/2023/a.json
test/acct-1/app2/2023/b.json
test/acct-2/app1/2023/c.json
test/acct-2/app2/2023/d.jsonIf you want to index only the log files that are generated by
app1, it can be better to define a regex liketest/acct\-[1|2]/app1/2023/.*to focus the traversal ontest/acct-1/app1...andtest/acct-2/app1....A regex such as
test/.*/app1/2023/01/.*with a wildcard in the second folder position could cause ChaosSearch to spend time traversing thetest/acct-1/app2andtest/acct-2/app2paths even though there will be no matches found below them.Wider folder wildcards could be helpful in sites where new accounts (
test/acct-3/app1...) are expected to be added over time, and their files are intended to be processed by the same object group. Some discussion with your ChaosSearch Customer Success team can help to craft the best regex for the expected log shipping bucket structure and object group setup.
An example window follows that shows a sample regex filter for CloudTrail log files.
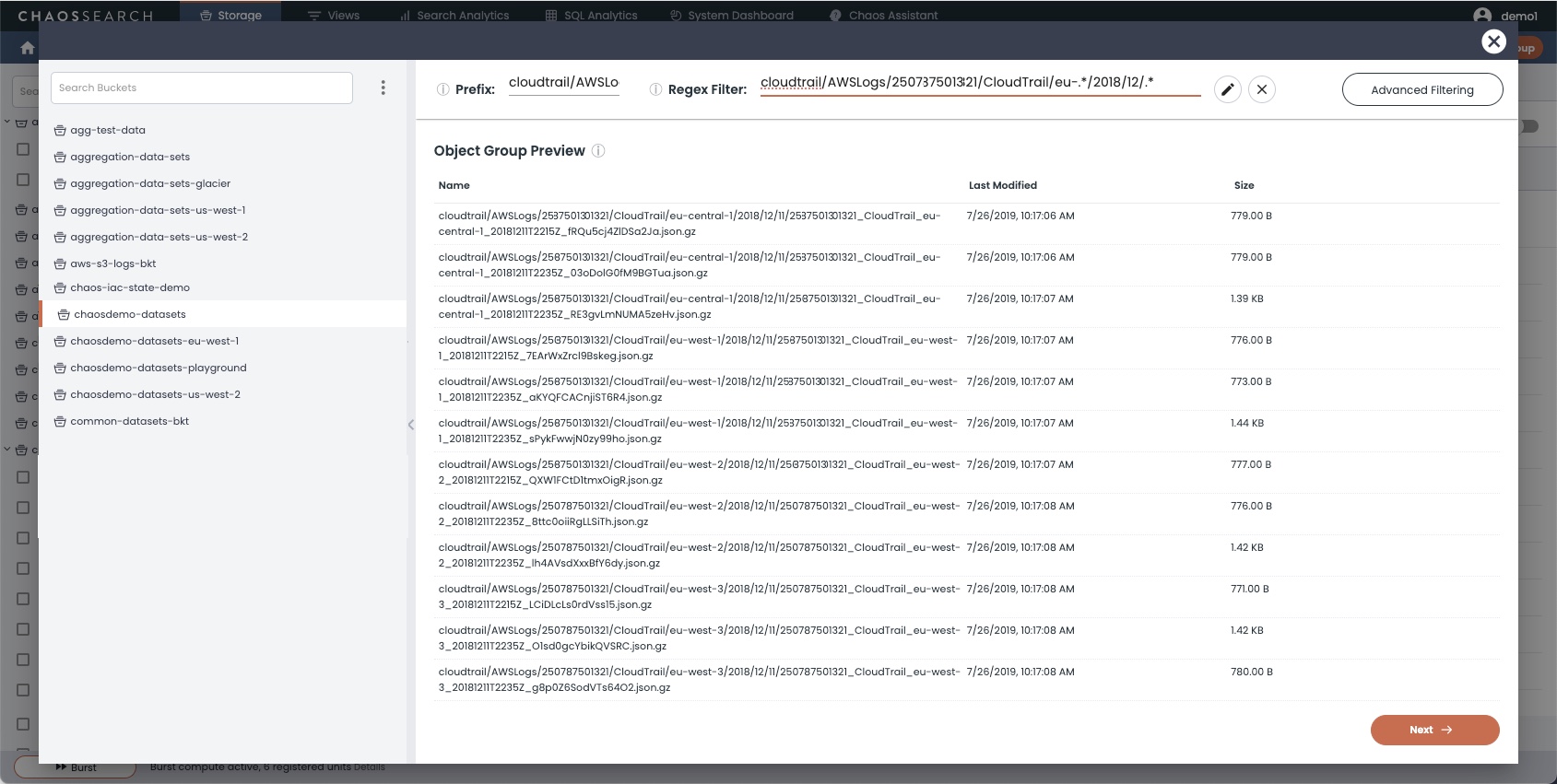
Regular Expression EditingSelecting a file in the preview list populates the regular expression for that file name. This can be a helpful way to pre-populate a regex to edit for refinement. Click the pencil icon to open a regex editor to modify the expression as needed and to see the effect on the pathname matches. Click the X icon to clear the prefix and regex settings if needed.
-
Optionally, click Advanced Filtering to display a window of additional options such as filters by file modification date, file size, cloud storage class, isolation keys (which can separate index data based on customer/multi-tenant naming or other methods), or custom object tags/metadata values.
-
After you select the files and specify any optional advanced filtering controls for the object group, click Next. The Content Preview window appears. A sample window follows for log files; see About the Content Preview for other examples and more information.
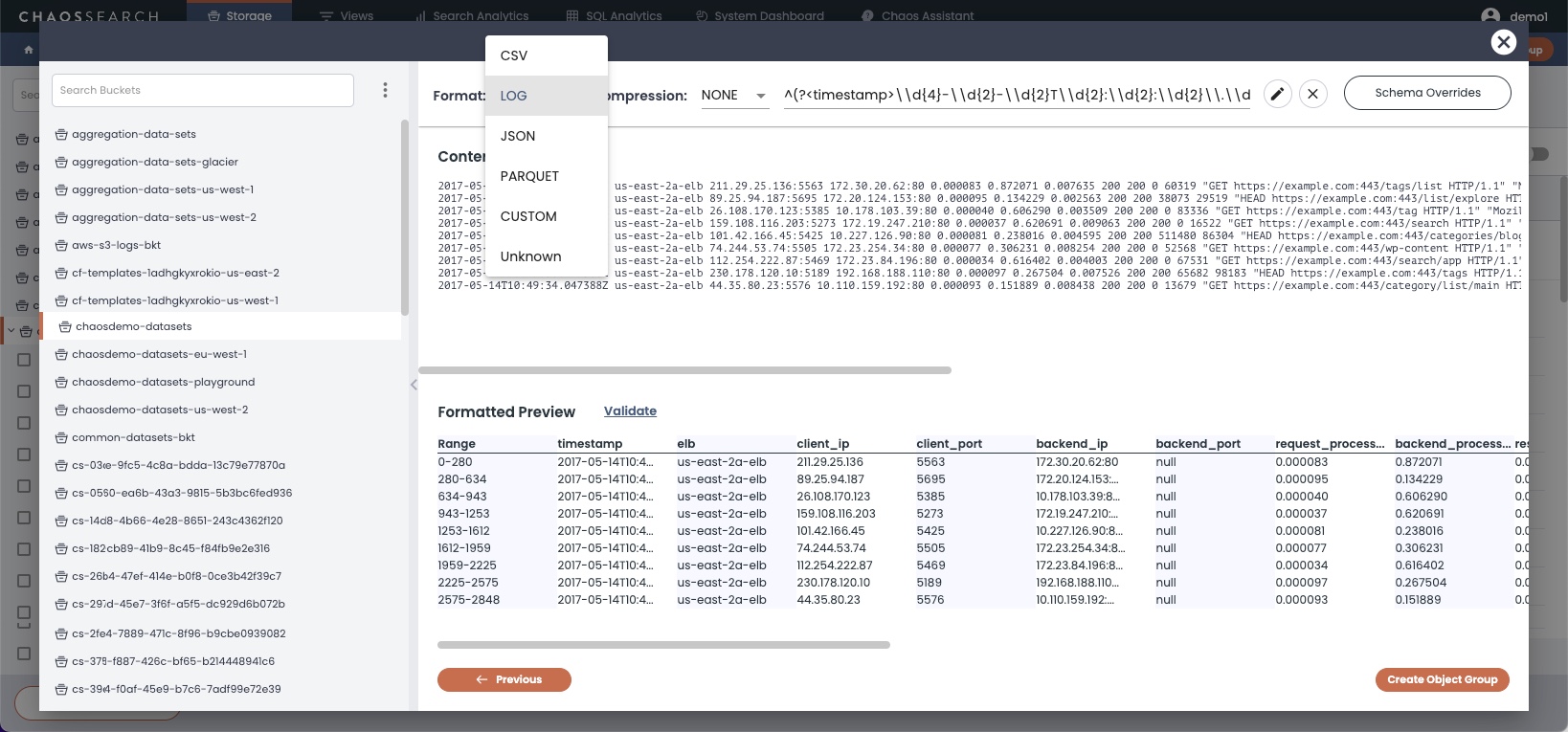
The content preview summarizes the format of the selected file(s) (such as CSV, LOG, JSON, PARQUET, CUSTOM, or Unknown) and the compression types (such as NONE, GZIP, SNAPPY, or SNAPPY-JAVA). CSV, JSON, and LOG files display other options to help with their index processing.
CUSTOM and Unknown FormatThe CUSTOM format enables the use of a custom parser, also referred to as a composite parser. Sometimes, files might require a custom parser for indexing. This setting takes a compression format and a JSON parsing rules definition, which is typically developed with assistance from the ChaosSearch Customer Success team have some cloud storage files that require ing files for indexing rules.
The UNKNOWN format is typically a LOG file format that does not match one of the log formats in the ChaosSearch parsing library. The typical step is to select LOG and specify a regular expression for parsing the log file to derive the fields.
SNAPPY-JAVA SupportObject groups and ingest services now support for snappy-java framing (
[magic header:16 bytes]([block size:int32][compressed data:byte array])*) for snappy-compressed files. See https://github.com/xerial/snappy-java#compatibility-notes for more information about framing formats in Snappy.
-
Optionally, click Schema Overrides if you want to override the auto-detected data type for one or more fields within the source files. ChaosSearch includes auto-detection routines that scan the matching storage files and auto-detect data types for numbers, strings, time values, and periods. Chaos Index also includes very flexible rules for customizing the schema for the files that will be ingested for the object group. Administrators can override the data type for one or more fields using Schema Overrides. This override enables virtual data transformations of the source content. Additional controls on the schema transformation page support the ability to include or exclude a list of specific fields for the index.
-
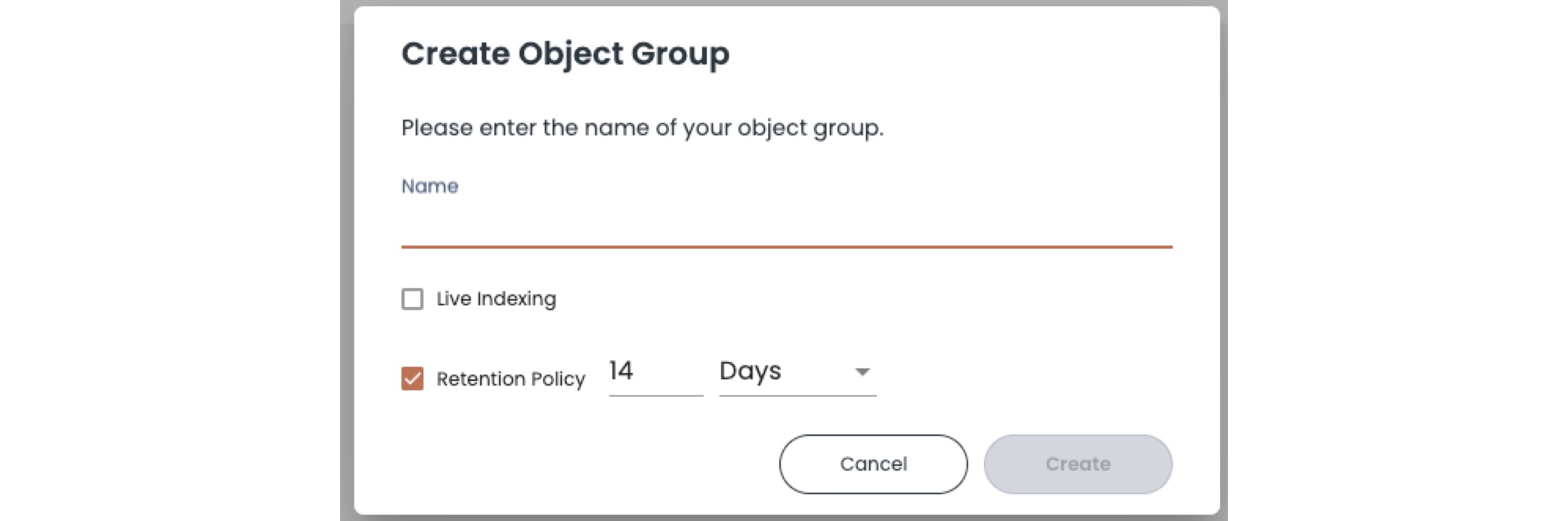
Click Create Object Group to complete the object group definition. The Create Object Group window appears.
-
Type a name for the object group.
-
Select whether you want to use static indexing or Live Indexing options for the group.
- Static indexing is the default. When you start indexing, Chaos Index runs one indexing pass to find and index the matching object storage files for the group.
- For live indexing, select Live Indexing and in the new field, specify an AWS ARN for an SQS messaging queue (or GCP Pub/Sub ID). When you start indexing, Chaos Index watches for SQS or Pub/Sub notifications to index any new matching cloud storage files after they are written to cloud storage and notification events are sent to ChaosSearch. Note that any matching cloud storage files that are already stored in S3/GCP will not trigger notifications for indexing by the object group.
-
In the Retention Policy field, select age-out time for the daily Intervals created for the object group. The default is to keep the daily intervals for cloud storage files that have modification dates in the last 14 days. You set a different number of days or months, or deselect the retention option to keep the daily intervals for an unlimited timeframe (no auto cleanup).
-
Click Create to save the object group. The Storage > Properties window appears with the new group selected for review.
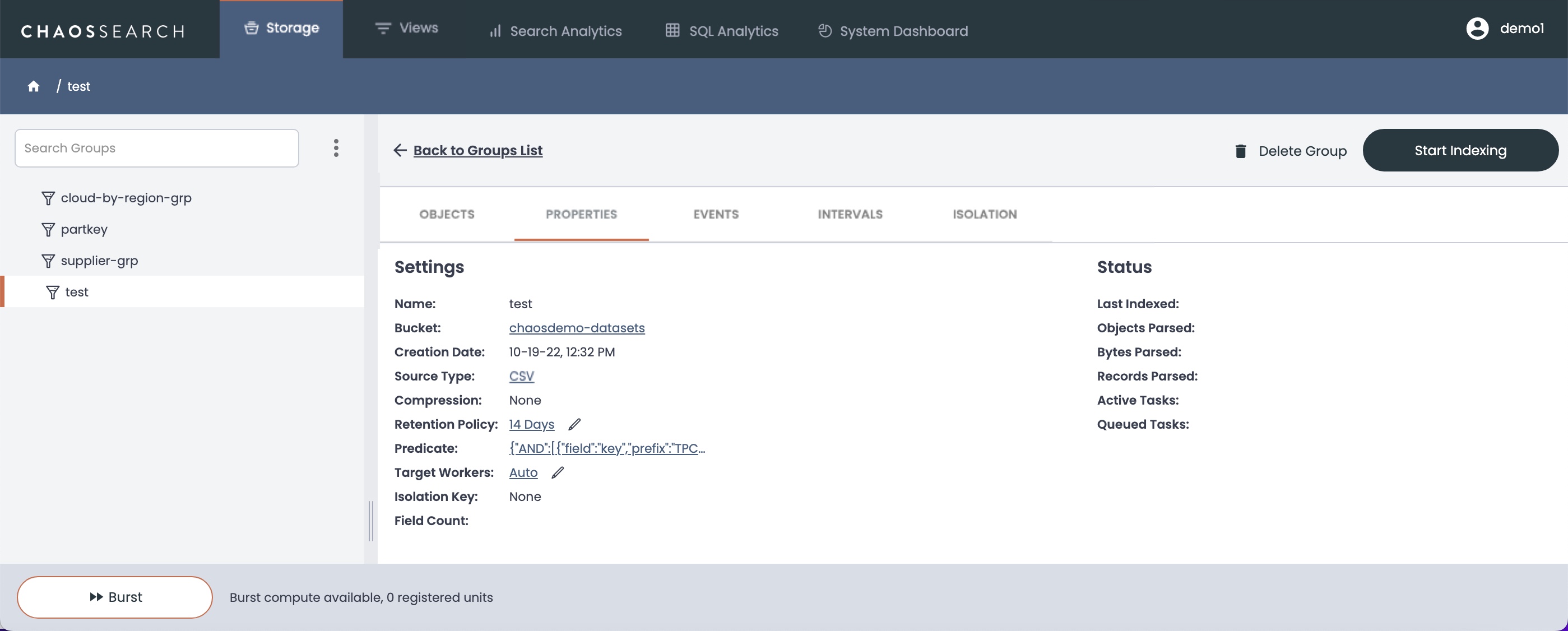
- Review the definition of the group to confirm that the information and configuration is correct, then click Start Indexing. See Indexing Your Data for the next steps.
Updated about 1 year ago
What’s Next
After you create an object group, confirm the settings and start indexing.