Indexing Your Data
Index your cloud storage objects to create the ChaosSearch data for visualizing and analyzing the information in the content.
ChaosSearch indexing is a deep data analysis of your cloud object storage content based on the rules defined in an object group. After you create an object group, start indexing to create the Chaos Index® daily intervals and multi-model analysis data that provide a lossless representation of your cloud-storage files.
Start Indexing
To start the indexing process:
- In the Storage area, select the object group that you want to start indexing.
- Click Start Indexing in the top right. (The button could be Restart Indexing if indexing ran previously and was stopped.)
Chaos Index reads the associated content, generating a proprietary data representation, and inferring the data structure (schema). The end result is one or more daily intervals appearing in the Intervals tab. If the object group uses static indexing, the indexing is finished after all of the referenced storage files are scanned and processed. If the object group uses live indexing, indexing runs in the background and updates when new matching files are written to cloud storage.
View Index Information
After files are indexed for the object group, the system displays a comprehensive report of your data. The Properties page is updated with a summary of the indexing Status, and a Data Types pie chart to summarize the fields that were discovered and created for the indexed data.
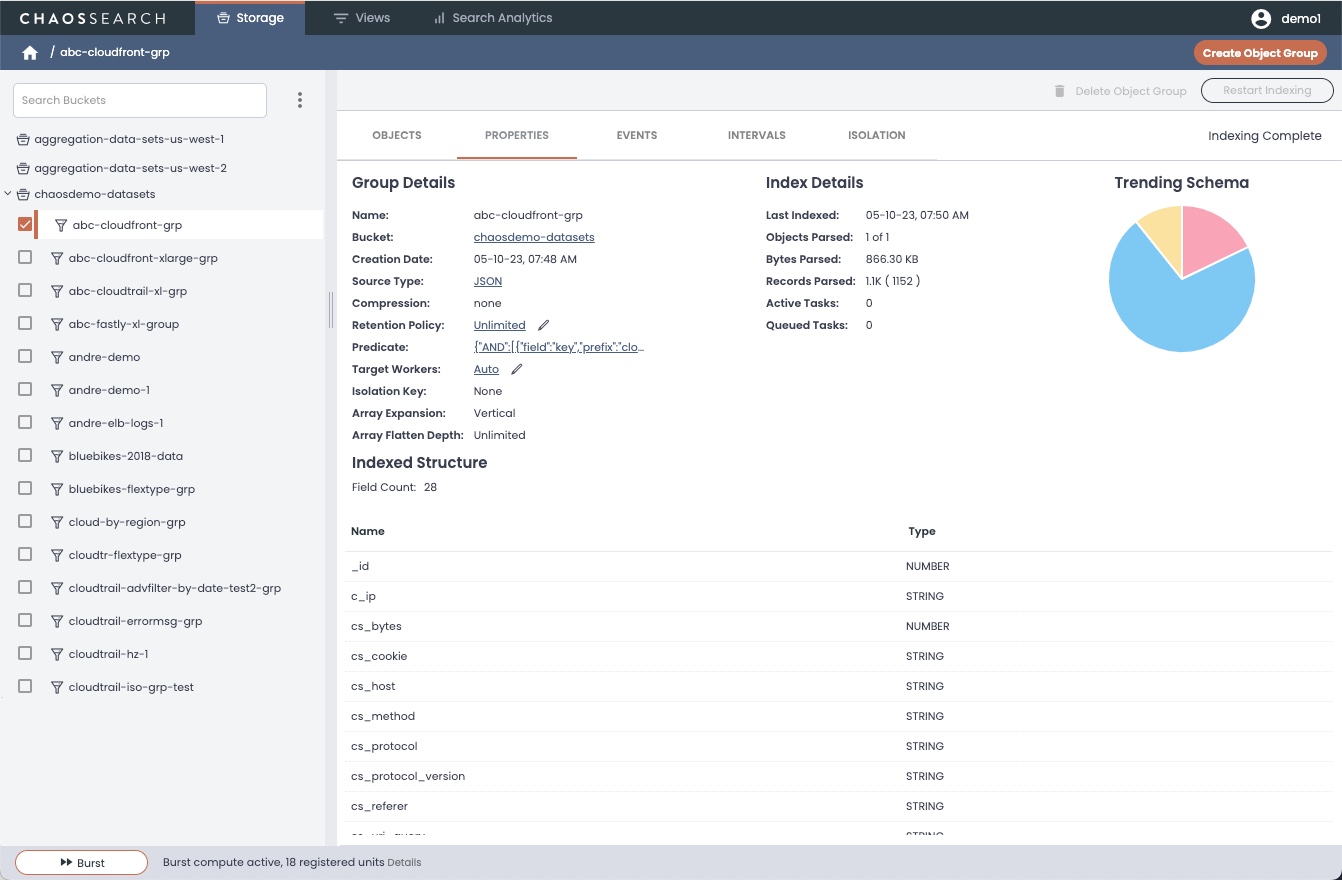
The Indexed Structure area summarizes the field information with a list of field names and data types.
Indexing Options
Live Indexing
With live indexing, ChaosSearch watches for notifications of new content written to the cloud storage bucket and indexes that new content. Live indexing is the typical option for most environments where the cloud storage bucket receives new objects to index on a regular cadence.
Live indexing requires the configuration of an Amazon Web Services (AWS) SQS integration or Google Pub/Sub integration (depending on the source cloud storage service) to notify the indexing service when new objects are available. For more information, see Live Indexing - Amazon SQS or Live Indexing - Google PubSub.
When you define the object group for the files that you want to index, ChaosSearch allows you to specify how to index your data. You first specify the file patterns, define any needed object and/or schema filters and column transformations, then you reach the Create Object Group window.
To configure Live Indexing, select the Live Indexing option and paste the ARN created for the AWS SQS service, or the GCP Pub/Sub Project ID. A sample window follows:

If you do not select Live Indexing, the indexing style defaults to static indexing. Static indexing is a one-time indexing operation that reads and indexes the available matching objects defined by the object group filters when you click Start Indexing. If new objects are added to the bucket after the static index is finished, they are not automatically indexed. It is possible to restart indexing for a static group to index files added later using the ChaosSearch API; contact ChaosSearch Customer Success for more information.
Within the Create Object Group window, you can choose a Retention Policy for Index Lifecycle Management.
Updated about 1 year ago