Datadog Integration
Combine your Datadog monitoring with ChaosSearch to support long-term history and centralized log analysis.
Datadog (a product of Datadog, Inc.) is an infrastructure monitoring and observability platform that provides an easy-to-start and fully-featured application that can ingest metrics, traces, and logs across applications, infrastructure, and third-party services. By monitoring systems in a single platform, it is a popular monitoring option among cloud-native companies.
One challenge of the Datadog environment is managing costs when organizations—and their log and event data—start to scale. Another challenge is centralized log management when teams want to search and analyze data from Datadog as well as from other apps and services, centralized in one tool.
The ChaosSearch integration with Datadog can help to maximize your savings. Eliminate rehydration processes and data retention costs by taking advantage of ChaosSearch for its cost-effective log data retention for operational and security analysis.
The ChaosSearch Difference
There are two ways to save money and increase data retention and analytical flexibility with Datadog + ChaosSearch:
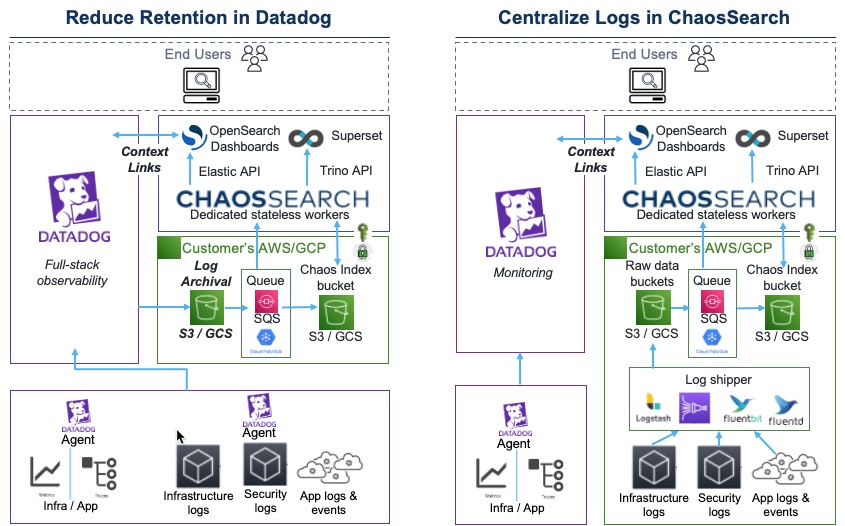
- Reduce Retention in Datadog: Use Datadog for full-stack observability, but reduce its log retention to 3 days and connect your log archival buckets to ChaosSearch. Leverage the ChaosSearch unlimited retention via OpenSearch Dashboards and Superset (in the ChaosSearch Console), and add context links in Datadog to seamlessly move from Datadog to the ChaosSearch console. Save 40% versus 30 days' retention in Datadog.
- Centralize Logs in ChaosSearch: Keep Datadog for monitoring, and centralize all of your logs in ChaosSearch to save up to 88% versus Datadog's 30 days' retention. Seamlessly move between Datadog and the ChaosSearch Console using context links.
About the Integration
The ChaosSearch-Datadog integration has two main setup steps (in addition to setting up the ChaosSearch and Datadog solutions):
- Create cloud-store locations such as Amazon S3 or Google GCP buckets to store your log files. If your log files are not already archived to a cloud-store bucket, you can configure the Datadog archiver to start saving those valuable logs to cloud storage.
- Grant ChaosSearch read access to read and index the files in those cloud-store locations. ChaosSearch processes the log files and creates the highly compact Chaos Index data; we store it in another cloud-store bucket (in your account) to which we have read-write access to hold the index data for your files, and then query it for analysis by your end-users.
After ChaosSearch has read access to the log archive bucket(s), ChaosSearch users can create object groups to start indexing the log files, and create Refinery views to search and visualize the data in those log files. Datadog users can add context links in their favorite Datadog displays to easily build a bridge to the ChaosSearch UIs. So, your Datadog users can stay in their favorite APIs for that real-time monitoring and APM tasks, and link to ChaosSearch when they need that deeper view into the wider, longer-term history of those log files for troubleshooting, root-cause analysis, trending, and other activities.
The following topics describe how to augment the Datadog experience at your site with the ChaosSearch Data Platform.
Updated about 1 year ago