CloudTrail JSON Files: Indexing Recommendations
Summary of recommendations for the JSON Flex and Chaos Index settings with CloudTrail logs
As you plan to index CloudTrail JSON files, consider these indexing recommendations for your object groups:
| Recommendation | Effect |
|---|---|
Use a default object group array flatten depth of 1, and Vertical expansion. These are settings in the Create Object Group interface controls. | Expand the top-level Any arrays below level 1 are flattened to JSON strings, unless you configure additional array selection settings to specifically manage subarrays and nested objects. |
Configure (If there are fields in these arrays of interest, JSON Flex view transforms can pull them out for search or filter controls.) | In many CloudTrail logs, these arrays could contain hundreds of fields, such as over 2000 If vertically expanded, there would be many hundreds of filtering fields in Search Analytics, creating a very difficult list for users to look through and use. Many fields are unlikely to be useful for analytics (not filtering fields). Using a JSON string reduces that filter bloat and confusion for users without losing the data from the index. |
Configure/blacklist the tags array to index as a JSON string. | The tags field is a common subarray within Records that could cause duplicate rows (and duplicate numeric field data used for analysis) during vertically flattening. By indexing tags as a JSON string, numeric fields are protected for metric aggregations, and row permutations are reduced. |
Index numeric ID values like Records.accountId and Records.recipientAccountId as string data types. | As a best practice, override numeric IDs to set their data type to string. This allows users to do string-like searches on the IDs and also avoids problems where leading zeroes of numbers might be truncated during indexing. |
Optionally, consider column renaming options to remove the Column renaming can be helpful for giving fields more user-friendly names. | Because the CloudTrail logs start with a Records array, the indexed fields will begin with that prefix, such as Records.errorCode and so on. A colRenames rule can remove the prefix and rename confusing field names to make fields easier to interpret and find. |
The following sections provide some examples of the JSON settings for the array processing, tags management, and column renaming.
With JSON Flex, JSON string columns have valuable analysis capabilities.The fields and properties inside a JSON string can be searched using standard text search operations in Search Analytics or SQL Analytics. With JSON Flex, there are more options for using the JSON string fields in the Refinery views. When you create the Refinery view for the object group, you can use the Materialize with JSONPath or Materialize with JQ schema transformation to create one or more materialized columns from a JSON string value for filtering and some limited aggregations. You can use the Treat as Nested JSON transform to make a JSON string searchable with Elastic nested query expressions.
Use JSON String Indexing for Large Records Arrays with Minimal Filtering Value
Records Arrays with Minimal Filtering ValueTo implement the recommendation to index very large arrays such as Records.requestParameters, Records.responseElements, and Records.additionalEventData as JSON strings, you create a JSON settings file that you can import to the Field Selection interface when creating object groups. (You can also pass this information in the format field payload of the createObjectGroup API.) A sample file follows:
{
"field_selection_policy": [
{
"excludes": [
"Records.requestParameters",
"Records.responseElements",
"Records.additionalEventData"
],
"type": "blacklist"
}
],
"vertical_selection_policy": [
{
"excludes": [
"Records.requestParameters",
"Records.responseElements",
"Records.additionalEventData"
],
"type": "blacklist"
}
]
}{
"bucket": "my-cloudtrail-objgrp",
"source": "my-cloud-bucket",
"format": {
"_type": "JSON",
"arrayFlattenDepth": 1,
"stripPrefix": true,
"horizontal": false,
"fieldSelection": [
{
"excludes": [
"Records.requestParameters",
"Records.responseElements",
"Records.additionalEventData"
],
"type": "blacklist"
}
],
"verticalSelection": [
{
"excludes": [
"Records.requestParameters",
"Records.responseElements",
"Records.additionalEventData"
],
"type": "blacklist"
}
]
},
...In the next topic for Refinery view settings, you can see how to configure these fields so that they can be searched using Elastic nested query syntax. Their information is still part of the index, but this change will reduce impacts to filter fields bloat.
Blacklist tags Array to Minimize Vertical Row Permutation and Duplication
tags Array to Minimize Vertical Row Permutation and DuplicationDuring vertical expansion of nested JSON arrays, subarrays can sometimes cause some unintended side effects.
In a CloudTrail Records array, there is a tags subarray that contains AWS tags used for metadata labeling. An abbreviated sample log follows:
{
"Records":[
{
"eventTime":"2021-03-06T21:22:54Z",
"eventName":"StartInstances",
"sourceIPAddress":"10.1.233.176",
"counter":100,
"tags":[
{
"t1":"val1",
"t2":"val2"
}
],
...During vertical flattening, the tags array will create an extra row for each tag field in the array, and those almost duplicate rows (which vary only in the tag field value) can impact aggregations.
For example, flattened rows might look like the following in the indexed data, as duplicate rows with only the tag val1/val2 differences:
0,2021-03-06T21:22:54Z,StartInstances,10.1.233.176,100,val1,...
1,2021-03-06T21:22:54Z,StartInstances,10.1.233.176,100,val2,...The extra rows affect the Discover Hits values for total records, inflate the totals for numeric fields (like counter) and aggregations like the number of StartInstances events, and so on.
To reduce the row permutations from flattening tags or similar arrays, you can blacklist the tags array to index it as a JSON string. These settings can be added to the JSON file that has the array settings from the previous section that you will import to the Field Selection interface when creating object groups. You can also pass this information in the format payload to the createObjectGroup API. A sample follows:
{
"vertical_selection_policy":[
{
"excludes":[
"tags"
],
"type":"blacklist"
}
]
}{
"bucket": "zzz-tags-blk-grp",
"source": "chaosdemo-datasets",
"format": {
"_type": "JSON",
"arrayFlattenDepth": 1,
"stripPrefix": true,
"horizontal": false,
"verticalSelection": [
{
"excludes": [
"tags"
],
"type": "blacklist"
}
]
},
...Just like the large Records.requestParameters and Records.responseElements arrays that were blacklisted in the previous section, the tags array content can be searched using Elastic nested query syntax.
Override the Data Type of Numeric IDs Fields
Fields like Records.accountId and Records.recipientAccountId usually contain all-number ID values like 012345678. These values are typically discovered and indexed as numeric fields, not as strings. As a result, ID fields typically cannot be searched like other string fields. Also, IDs with leading zeros might be truncated when they are indexed, resulting in an incorrect ID value.
Numeric ID fields should not be used in metric aggregations like sums or max/min calculations. Although they look like numbers, they should be treated just like alphanumeric name strings.
In typical CloudTrail data, the ID fields could include the following: Records.accountId, Records.recipientAccountId, Records.userIdentity.accountId, Records.resources.accountId, and Records.userIdentity.sessionContext.sessionIssuer.accountId. It is a good practice to change the data type of these fields to String to match the purpose of the content and to support string searches against those fields.
With ChaosSearch, you can override the data type of numeric ID fields in the object group Schema Overrides. A sample screen follows:
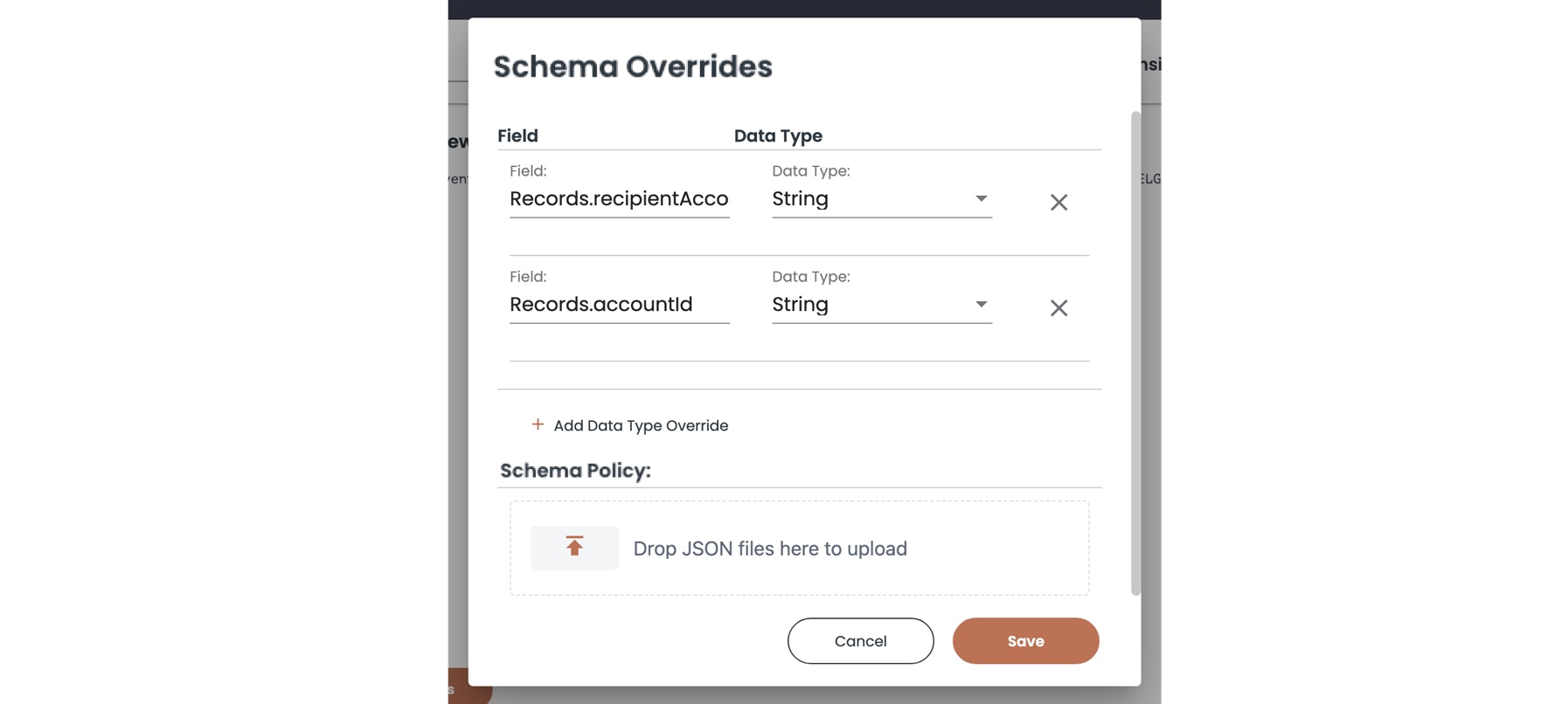
You can also pass this information in the payload to the createObjectGroup endpoint, for example
"colTypes": {
"Records.accountId": "String",
"Records.recipientAccountId": "String",
"Records.userIdentty.accountId": "String",
"Records.resources.accountId": "String",
"Records.userIdentity.sessionContext.sessionIssuer.accountId": "String"
}JSON Column Renaming Recommendations
As shown in the sample CloudTrail log earlier in this topic, the JSON property names could be very long values due to the concatenation of nesting levels for arrays or object properties. For CloudTrail fields in the indexed data, many or all of the fields will begin with the prefix Records. because of the main array. Some sample field names follow:
Records.userIdentity.invokedBy
Records.tlsDetails.clientProvidedHostHeader
Records.eventCategory
Records.errorCode
Records.userIdentity.sessionContext.ec2RoleDelivery
Records.serviceEventDetails.statusMessage
Records.additionalEventData.SwitchTo
Records.serviceEventDetails.DocumentName
Records.additionalEventData.configRuleArn
Records.serviceEventDetails.snapshotId
Records.serviceEventDetails.IsS3EncryptionEnabledThe Records. prefix string is redundant and often can make the eventual Refinery view column names more complex to read and find desired fields, especially when the names are very long. Sometimes internal field names are not very meaningful, and they could be renamed to make them much clearer to users.
ChaosSearch object group controls include a column rename feature that can make these name changes to create shorter and more user-friendly column and filter names in their views. The colRenames syntax is part of the createObjectGroup API, but not yet part of the Create Object Group user interface (so they cannot yet be passed into the Field Selection file settings). Some sample column rename settings are shown below:
"colRenames": {
"Records.userIdentity.invokedBy": "userIdentity.invokedBy",
"Records.tlsDetails.clientProvidedHostHeader": "tlsDetails.clientProvidedHostHeader",
"Records.eventCategory": "eventCategory",
"Records.errorCode": "errorCode",
"Records.userIdentity.sessionContext.ec2RoleDelivery": "userIdentity.sessionContext.ec2RoleDelivery",
"Records.serviceEventDetails.statusMessage": "serviceEventDetails.statusMessage",
"Records.additionalEventData.SwitchTo": "additionalEventData.SwitchTo",
"Records.serviceEventDetails.DocumentName": "serviceEventDetails.DocumentName",
"Records.additionalEventData.configRuleArn": "additionalEventData.configRuleArn",
"Records.serviceEventDetails.snapshotId": "serviceEventDetails.snapshotId",
"Records.serviceEventDetails.IsS3EncryptionEnabled": "serviceEventDetails.IsS3EncryptionEnabled",
}"As a good practice, when you create some smaller sample CloudTrail object groups, review the field names created for the object group and evaluate whether the field names could be better by removing the Records. prefix and by other renaming to shorten or change the names to make them easier when they appear as fields in the Refinery view for analysis.
Updated about 1 year ago