JSON Log and Event File Challenges
JSON log and event files are very valuable sources for information, but there are challenges for indexing them efficiently.
JSON files can be complex, and their structure can present some indexing challenges. However, JSON is not impossible, and ChaosSearch has several features designed to solve the challenges.
This topic offers an overview of JSON syntax and the indexing challenges to be aware of.
JSON Syntax Overview
The JSON syntax defines two structures: objects and arrays.
Objects
An object is enclosed within braces {}, and is formed one or more comma-separated name-value pairs (called properties) where the name is a string, and the value can be a string, number, object, array, true, false, or null.
A very simple JSON structure with two objects follows:
{
"obj1" : "this is a string",
"obj2" : "true"
}An object could have nested objects, also set apart in braces {}, as shown in the customer example below. The street_address fields are not nested, for comparison.
{
"customer": {
"lastname": "Smith",
"firstname": "Maria",
"cust_id": "12345"
},
"street_address1": "123 Main Street",
"street_address2": "Apartment B"
}During indexing, objects and nested objects are indexed as columns. So, using the example structure above as an example, the objects would index as 5 columns, for example:
customer.lastname, customer.firstname, customer.cust_id, street_address1, street_address2
Note that nested objects include the nesting level names in a dot-separated format to uniquely identify their position in the JSON structure—so customer.lastname, not lastname The name could have multiple dot names when they are inside deeply nested sublevels.
Arrays
An array is enclosed within brackets [] and contains zero, one, or more comma-separated elements or values. The values within an array can have the same or different types, and can include objects and nested arrays. For example, contacts is a simple array of contact phone numbers.
{
"contacts": [
{
"home": "555-123-1234",
"mobile1": "555-234-5678",
"mobile2": "555-123-4567"
}
]
}In a more complex example, the customers array has objects for some customer details and a nested array of contacts:
{
"customers": [
{
"lastname": "Smith",
"firstname": "Maria",
"cust_id": "12345",
"str_addr1": "123 Main Street",
"str_addr2": "Apartment B",
"contacts": [
{
"home": "555-123-1234",
"mobile1": "555-234-5678",
"mobile2": "555-123-4567"
}
]
},
...
]
}As with nested objects, array fields can have names with dot-notation to show their position in the structure (e.g., customers.contacts.home). Arrays have indexing challenges, even for simple ones like the customers example.
JSON Flattening
A challenge for indexing JSON files is how to efficiently index any arrays that are present in the structure. Arrays must be converted into a two-dimensional representation of rows and columns—like a relational table. This is referred to as flattening the JSON structured format.
With arrays—especially complex, highly nested arrays—flattening can sometimes expand the objects and arrays into a significant number of rows and columns. This could require a large amount of storage resources to hold the flattened data, and is often referred to as the JSON permutation explosion.
Horizontal and Vertical Expansion Options
There are two types of expansion methodologies used for flattening JSON arrays:
- Vertical expansion flattens arrays into rows of values with the columns applicable to each row.
- Horizontal expansion flattens arrays into one row with many columns of values.
For example, vertical flattening for the simple customers example in the previous section results in three rows for this one customer record, where the majority of columns are identical except for the last column flattened from the array:
customers.lastname, customers.firstname, customers.cust_id, customers.str_addr1, customers.str_addr2, customers.contacts.home
customers.lastname, customers.firstname, customers.cust_id, customers.str_addr1, customers.str_addr2, customers.contacts.mobile1
customers.lastname, customers.firstname, customers.cust_id, customers.str_addr1, customers.str_addr2, customers.contacts.mobile2With horizontal array flattening, the sample array and nested array results in one row for each array element, with unique columns for the nested contacts array members shown at the end, for example:
customers.0.lastname, customers.0.firstname, customers.0.cust_id, customers.0.str_addr1, customers.0.str_addr2, customers.0.contacts.0.home, customers.0.contacts.0.mobile1, customers.0.contacts.0.mobile2
If the customers array had another element, the indexed data row would have another set of columns with names like customers.1.lastname ... customers.1.contacts.0.home and so forth. Using horizontal flattening, rows can become very wide with many unique columns.
The following image shows how expansion flattens arrays into rows and columns. As shown in the example, vertical flattening can result in nearly-duplicate rows, and horizontal flattening can result in a wide row with distinctly named columns for array members:
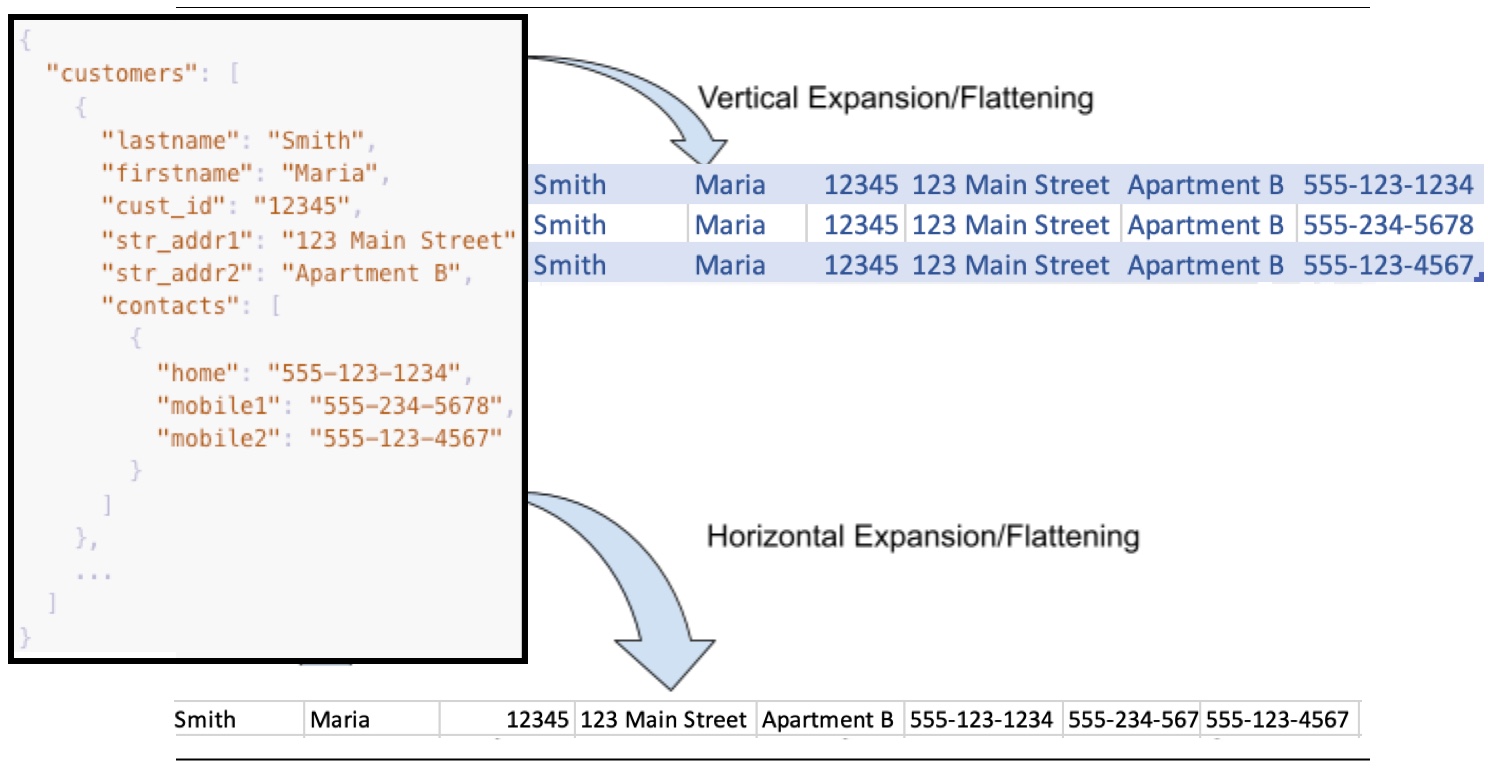
Array Depth Expansion
JSON arrays can have nested elements with several depth levels. So, a JSON array might have a structure similar to the following skeleton, with arrays nested inside other arrays.
"array1": [
{
"array2": [
{
"array3": [
{
"array4": [
{
"arrayx": [
{
...The nested array depth level can contribute significantly to the permutation explosion when flattening JSON files. Tests with JSON log files from some common application services show that one highly nested JSON array could vertically flatten to millions of indexed rows—or horizontally to one row with millions of columns.
JSON String Blobs
As one way to guard against permutation explosions, one option is to flatten arrays and deeply nested objects into one column, a JSON string blob that contains a concatenated list of all the objects across the array and nesting levels. JSON string blobs are just ordinary strings, and thus can only support basic string filters and searches. The value within them is usually unavailable for use in aggregations or comparison.
Returning to the customers example, flattening the sample structure to a string blob from the top level would result in a row with one column that contains the concatenated values, for example:
[{"lastname":"Smith","firstname":"Maria","cust_id":"12345","str_addr1":"123 Main Street","str_addr2":"Apartment B","contacts":[{"home":"555-123-1234","mobile1":"555-234-5678","mobile2":"555-123-4567"}]}]Vertical Expansion, Arrays, and Numeric Fields
If you use vertical expansion, be sure to watch for JSON structures with arrays and the effect on numeric fields in the data. For example, when you use vertical expansion for JSON structures that have a format like this:
{
"bytes": 123,
"name": "string",
"tags": [
"success",
"info"
]
}Vertical expansion of the tags array can result in two rows where the bytes and name objects are duplicated while flattening the tags array:
123 string success
123 string infoFor bytes and name, the resulting rows can affect aggregations such as count() or sum() functions. For example, because there are two rows with the same bytes value, a sum of the bytes column would result in a double-counted value of 246, not 123. If the string column is used for count aggregations, the extra row adds +1 to the count. To avoid the vertical row expansion impact to these types of fields, you could flatten the tags array to a JSON blob, or if tags is not important for analysis, you might consider dropping that array from the source files pre-indexing, which might mean re-pipelining the source data for some apps (but not ChaosSearch).
Avoid the Toil, Time, and Cost Hurdles with JSON Flex
JSON files are very valuable sources of information, but they present challenges for permutation explosion, storage requirements, how to flatten arrays and nested objects for indexing. Administrators sometimes spend significant time and energy to evaluate the JSON files and their content, and to experiment with alternatives like re-pipelining/re-ETLing source files and trading off data visibility, or leveraging JSON blobs to avoid permutations. ChaosSearch JSON Flex offers a much easier solution for simplifying the indexing and analysis of complex JSON files.
Updated about 1 year ago
What’s Next
Read more about the features of JSON Flex for solving the JSON array dilemma.