ChaosSearch Resource Framework
Learn about object groups and views, the building blocks of the ChaosSearch framework.
ChaosSearch uses two important resource types to build the framework for data ingestion and data observation:
- Object groups organize and filter the source objects within cloud storage and automatically index the raw data into the Chaos Index data to support querying (using views) by popular Elastic and SQL tools or direct API access, again, with no data movement outside of customer cloud storage.
- Views are published, dynamic lenses into the Chaos indexes supporting the analysts of static and live streamed data. Views support querying in Elastic and SQL interfaces, offering inline isolation and filters, as well as instant schema transformations. They are also RBAC-controlled to ensure users can focus on their analysis areas.
Storage – Object Groups
An object group is a virtual folder or bucket of object files that filters and organizes specific objects to analyze. The output for an object group—the Chaos Index—is a highly compressed, lossless, full representation of these objects, while supporting multi-model multi-model query access (i.e., Search, SQL, and GenAI). It is the first of two parts (with views) that make up the Chaos LakeDB ingestion pipeline.
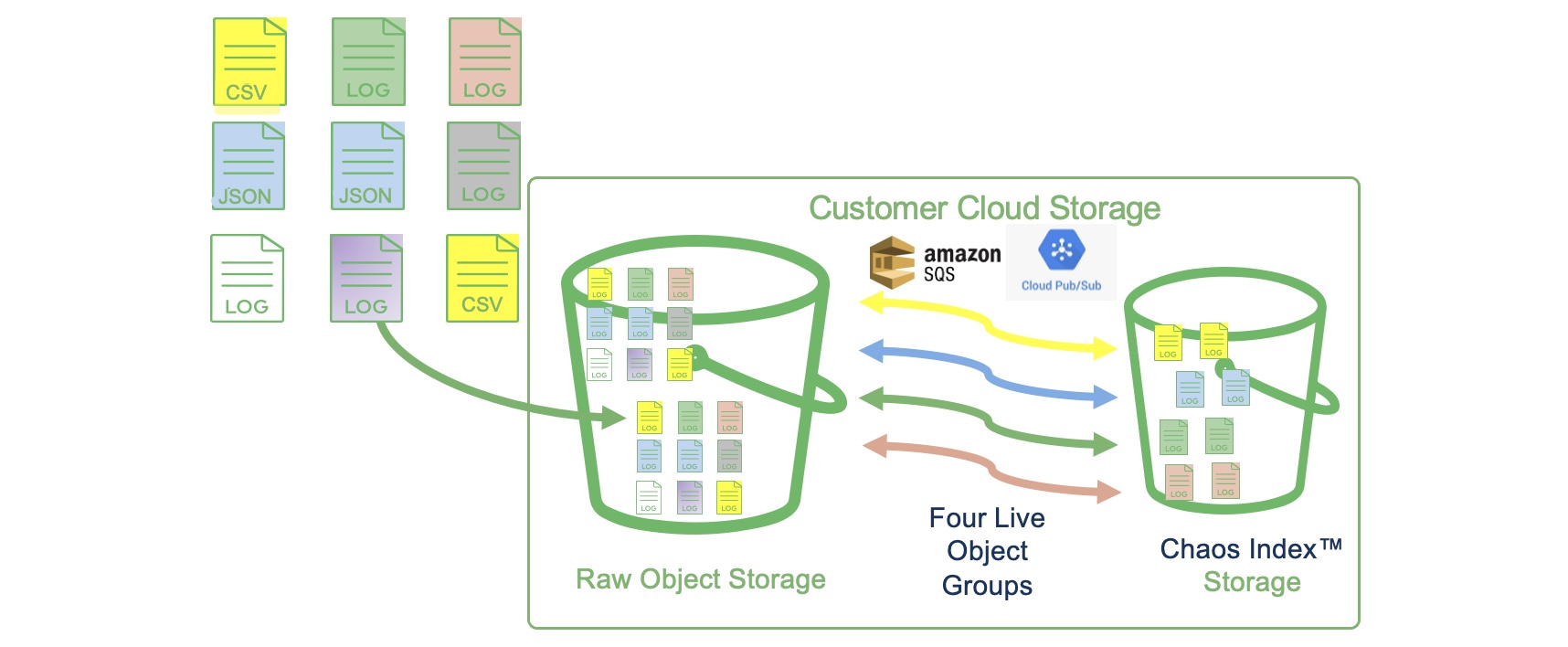
The indexed data for each object group is rolled up into configurable daily interval files where object "put" time or internal timestamps of rows drive interval co-location. The intervals can be separated into specific stream portions (referred to as data isolation) based on rules that can separate data streams by specified filter criteria. When isolation is used, ChaosSearch indexing creates a daily interval per isolation key to enforce that data separation in storage.
ChaosSearch does not use raw object files for direct analytics, it leverages the Chaos index data, which is orders of magnitude smaller, thus reducing storage costs and increasing compute performance. As new data is put into cloud storage, the Chaos Index can live index (ingest) new data and store its index content in the designated customer cloud storage bucket, from which all operational search/query is performed.
Object Group Configuration Properties
Object groups have built-in auto-detection and data typing of the source content. Object groups are also flexible, with configuration features that can customize indexed data and adapt to specific content and analysis needs without the toil of an ETL pipeline. An object group definition includes the following kinds of configuration properties:
- Location rules where the related files are stored in cloud storage buckets
- Filtering rules based on regular expressions specifying files within an object group
- Indexing rules to customize field names or data types and/or specifying the fields to include/exclude, as well as isolation rules to separate indexed data
- Tokenization rules to optimize queries where words and symbols can be uniquely and specifically indexed so that future analysis is executed during query plan scoping
- SQS policy ARN for notifying the group when new objects are put into cloud storage, to trigger automatic indexing of the objects
ChaosSearch can index a variety of the popular data format types such as CSV, LOG, JSON, or Parquet, as well as handle common compression algorithms (e.g., GZIP, Snappy, Snappy-Java, or none). ChaosSearch is extensible, and can add new formats or compression algorithms when support is needed.
Views – Patterns/Tables
Views, also called the Data Refinery, are virtual lenses into the indexed data for one or more object groups. They are the ChaosSearch equivalent to relational tables, Elastic index patterns, datasets, or similar resources. Views allow users to define how to access and query the indexed data. They are flexible definitions that can support many different kinds of analytic tools, as well as API access.
Views also have additional features such as RBAC support, dynamic change in schema, and on-query virtual transformations, delivering time-saving analytics.
The Chaos Refinery is comprised of the following components:
- Abstract Lenses for filtering data so that users can focus on only the datasets one needs, across one or more streams of data
- Virtual Schema-on-write controls to materialize and transform fields within the indexed data to view columns that the analysts/users want, without requiring physical ETL-ing
- Multi-Model/-Modal Access where one logical representation (the view) provides Search, SQL, and Conversational AI without the time, cost, and complexity of multiple databases
View Configuration Properties
As a partner with object groups, views include very flexible data transformation controls that help to frame data into clear definition for analysis, and to filter the data that users can see to limit the access to granular visibility rights. A view definition includes the following kinds of configuration properties:
- One or more object groups, as well as interval ranges and and streams of data (e.g., isolation keys) that the view will query or analyze
- Schema transformation rules (i.e., filters and manipulation) to control the presentation and use of the fields within the indexed data as fields/columns in the view
- Advanced Options such as View Caching where a particular query result can be cached and dynamically updated during live ingestion. Views can also case-insensitive querying, although case-sensitive is the norm for performance.
The Chaos Schema
Views provide a virtual layer over the indexed data with specific changes that can more tightly control the columns and data needed by users. These transforms are flexible options for specifying how to use or render the indexed data content without the burden of custom ETL pipelines or additional indexed data duplication to make those types of custom changes available for analysts.
Schema transformations can dynamically change and materialize columns of the indexed data; they changes are saved as part of the view definition, to make the customizations available for analytics and querying. Transformations only live within the context of the view, where users can benefit from them and see their effects; any other views against the same object groups would see the indexed data as stored in its original form with any transformations as defined in the other views.
Updated about 1 year ago
What’s Next
Learn how ChaosSearch reduces the toil of the ETL pipeline