Free Text Searches
A free text search looks for matching values in all the indexed data for a specific Refinery view, across all columns, for the specified time frame.
Free text searches return a wide set (or all) matching records within a specified time frame. They require more time and work to complete than a field-level search in large datasets because they search across all fields. If you have a small data set and you are not sure whether a value might be in the indexed data, a free text search could be helpful for hunting in the dataset.
The following example shows a free-text Discover search for the term Opera in the sample index that has one million records:
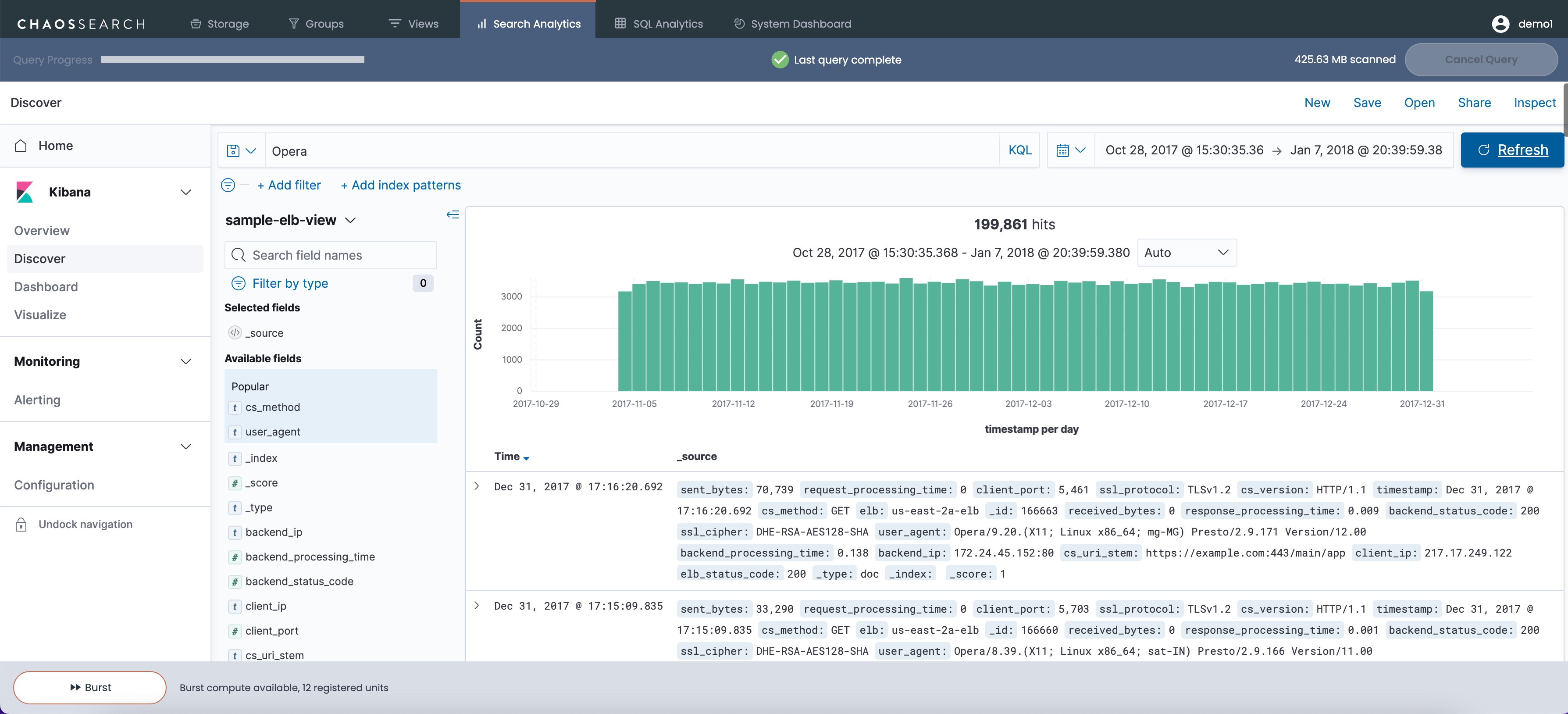
After the free text search, the results narrow to just under 200,000 results that contain the term Opera in any field. The results will not match against extensions like Operas or Operations or opera (lowercase) if the Refinery view is case-sensitive, which is the typical setting for most views. Searching for a term like error in very large indexes could return millions or even billions of results, and require more compute/worker resources than field-level searches to complete.
Free text searches are faster in ChaosSearch compared to other solutions.Although free text searches require more processing and time than a field-bound search, free text searches in ChaosSearch are much more performant/faster than free text searches in other solutions, thanks to the Chaos Index design where they behave more like key-value lookup searches.
In free-text, you can use wildcards like *categor* to find results that include categor such as category, categories, decategorize, and so on (again, with case-sensitive results using the default view setting). If a view is case-insensitive, the results will match on any letter case. Case-insensitive searches take more time for case-insensitive matches, especially for a wide search across a large body of indexed data. The following sample shows a wide search that is narrowed by a free text search for *categor*:
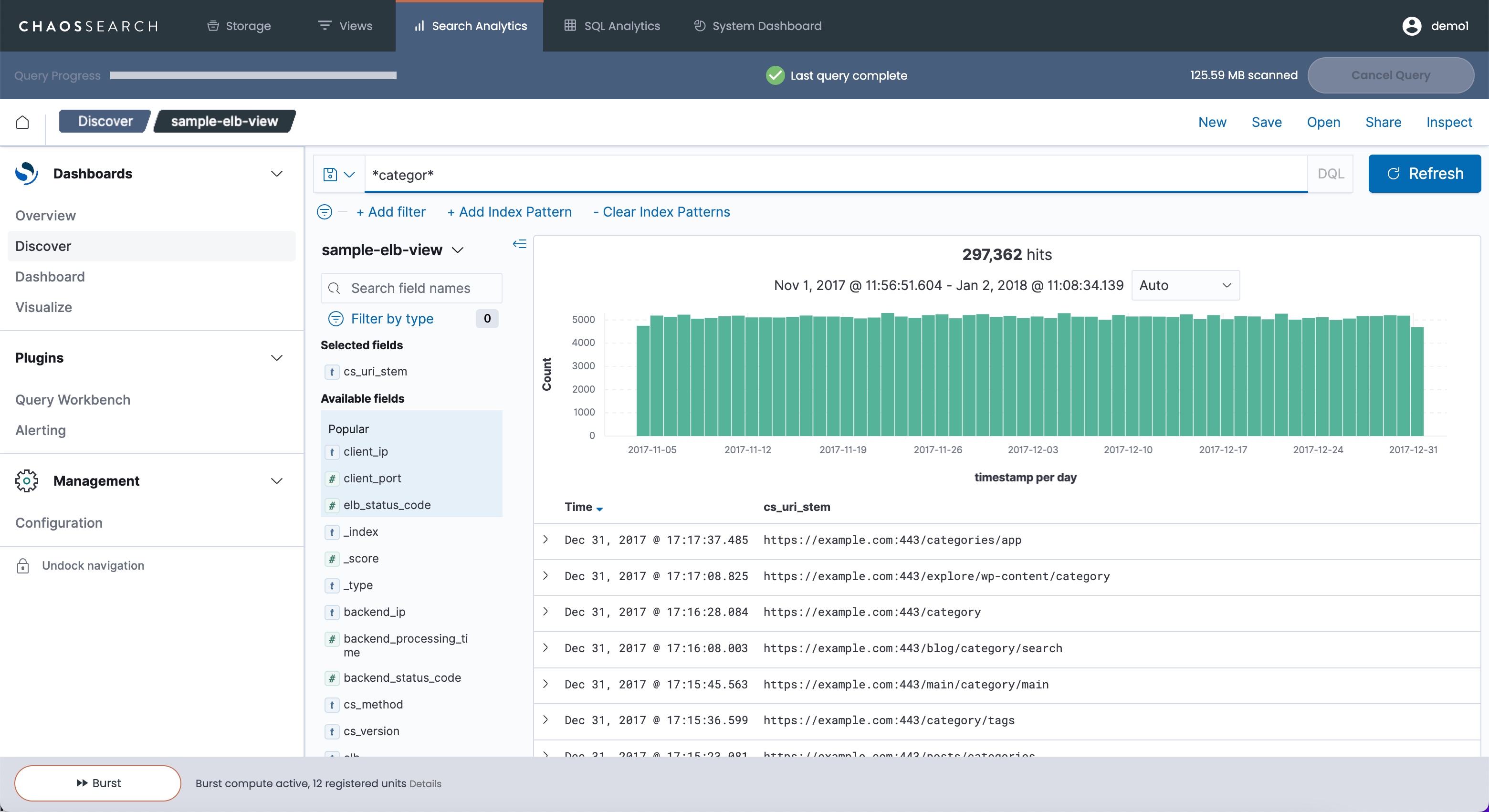
Free text searches can be useful, but in general, free-text searches are not the best type of search to run with data at scale. It is a better practice to "bind" your searches to a field to narrow the search for performance.
Updated about 1 year ago