Walkthrough: Creating Object Groups with JSON Flex
Review the steps for creating object groups that use JSON Flex options to unlock the value in your JSON log and event files
ChaosSearch object groups have many features for selecting and indexing the log and event files in your cloud-storage locations.
This topic presents a high-level walkthrough of the UIs and steps to create object groups to index JSON files, and the various JSON Flex and standard features that you can use. Details about the UIs and concepts are available in linked topics below.
Have a list of the indexing settings you want to try?As a reminder, some pre-planning and small-scale testing can help to you to prepare the list of the settings and features that you'll want to use in your object groups.
Specify the Files to Index
When you create an object group in ChaosSearch Storage, the first step for object group creation: identify the prefix or pathname expression that will select the raw JSON files in your cloud-storage buckets to index. You select the cloud-storage bucket that holds the files, then use Prefix and Regex Filter to select the files to index.

Set the Default Group Array Options
After you select one or more JSON files to index, the object group Content Preview window displays the information about the detected JSON format, file compression, and JSON array flattening controls with a depth of NONE and a default array expansion of Vertical.
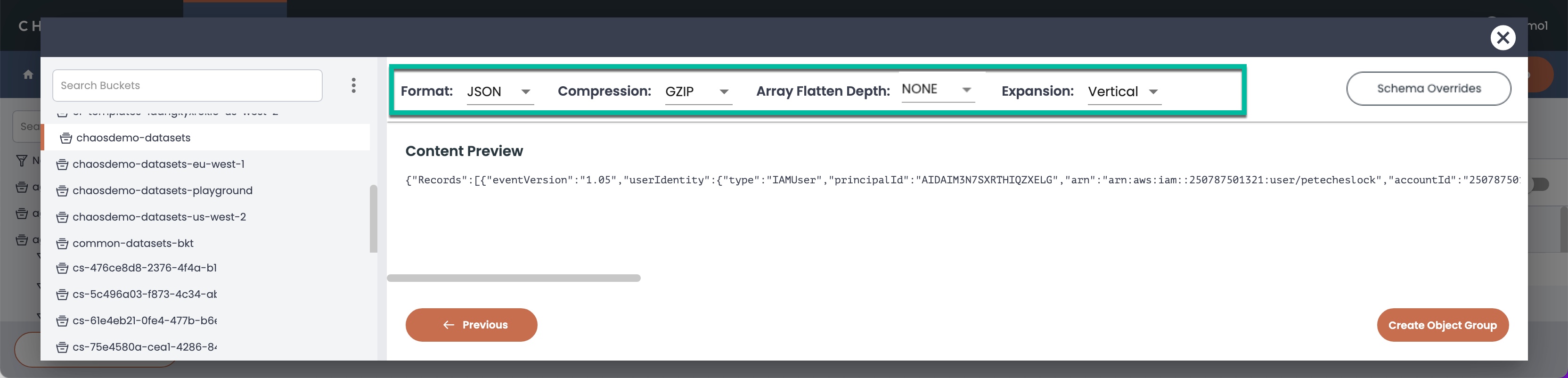
You use the flatten depth and Vertical or Horizontal expansion settings to set default array expansion rules for the JSON files in the object group. So, for example, for CloudTrail files, use a recommended depth of 1 and Vertical expansion. You can specify the options that you want to use based on your index planning or Customer Success recommendations.
Field and Array-Specific Overrides
The Schema Overrides button in the top right corner of the Content Preview window opens the Schema Overrides window with features for virtually transforming the data type of a column, or for using a preconfigured JSON file of schema policy rules to control how the source content is indexed.
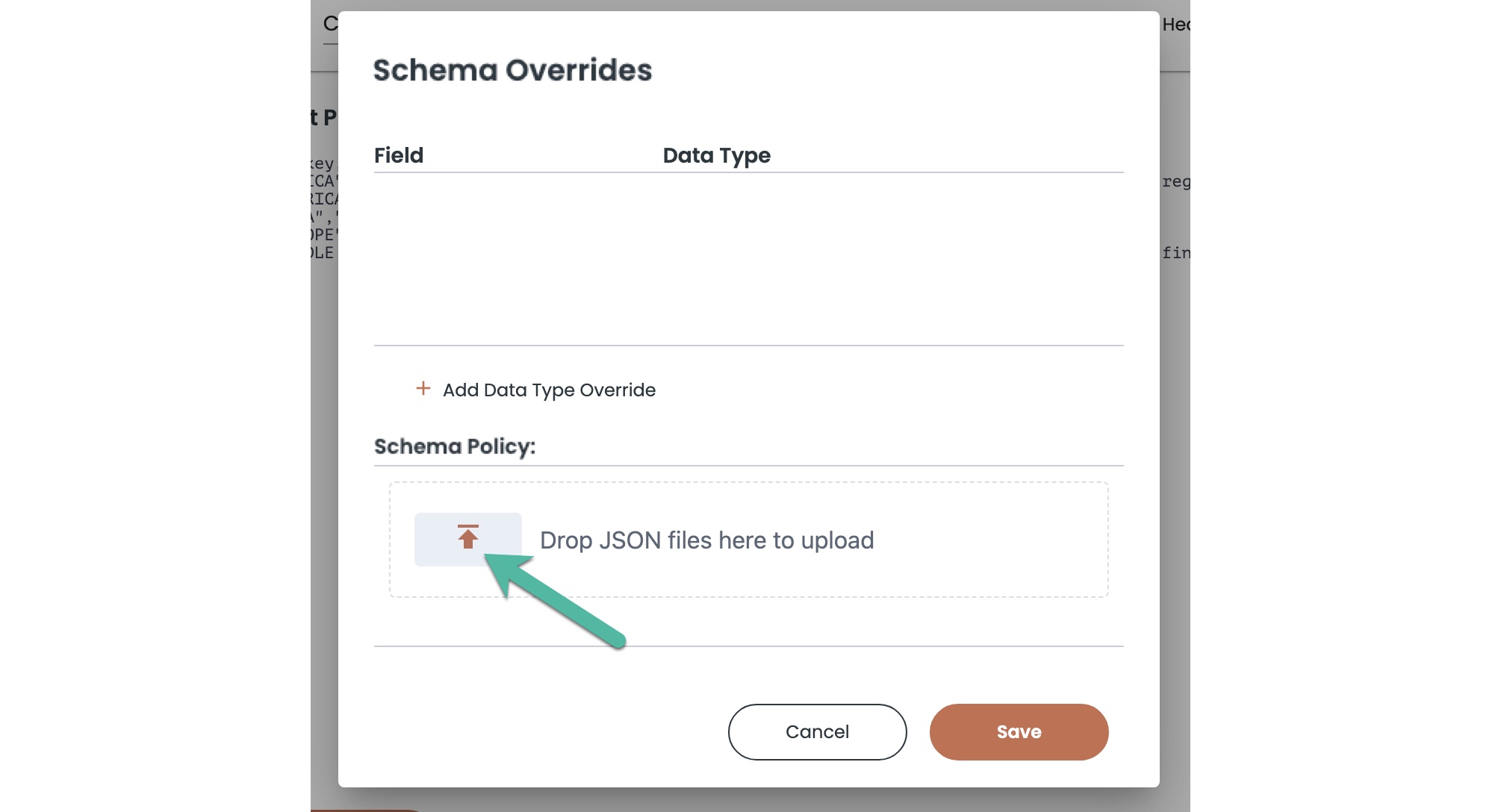
These schema policy settings are where you can specify the JSON Flex options like:
array_selection_policyto index (or exclude) specific named arrays. You can control the arrays that you do or do not want to index, and thus reduce index storage, search column complexity, and vertical row permutations.vertical_selection_policyto specify the arrays that you want to vertically expand when an object group uses horizontal expansion by default.field_selection_policyto specify JSON nested objects that you might want to index as JSON strings (rather than separate fields).
With JSON Flex, object groups offer layers of options that help you to index your JSON file content the way that you want to.
Updated about 1 year ago