Incremental Results Loading
An overview of the incremental results feature and how to use it via API
For longer-running queries, ChaosSearch added the incremental loading feature to provide intermediate results for improved user feedback.
For example, this is visible when a user runs a longer Discover query within the ChaosSearch console interface. As the search runs, results stream in periodic updates to the histogram chart. The result is an active, visible update to the display, along with the progress bar that shows the status of the index segments being scanned and processed. Users have visual cues about the Discover scan size, and whether it is still running, until the search is complete.
The following image shows a Discover search running in the ChaosSearch console with incremental results loading.
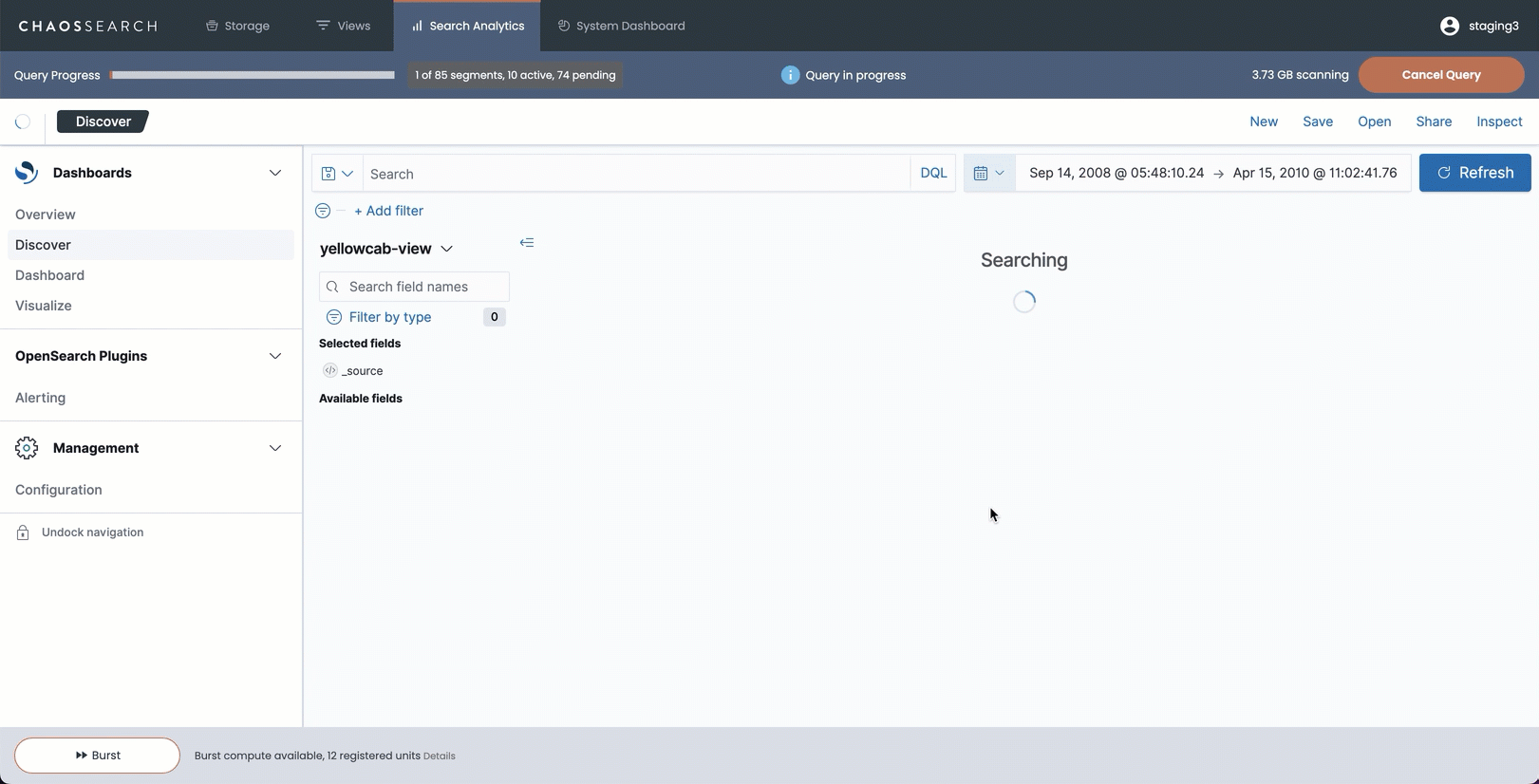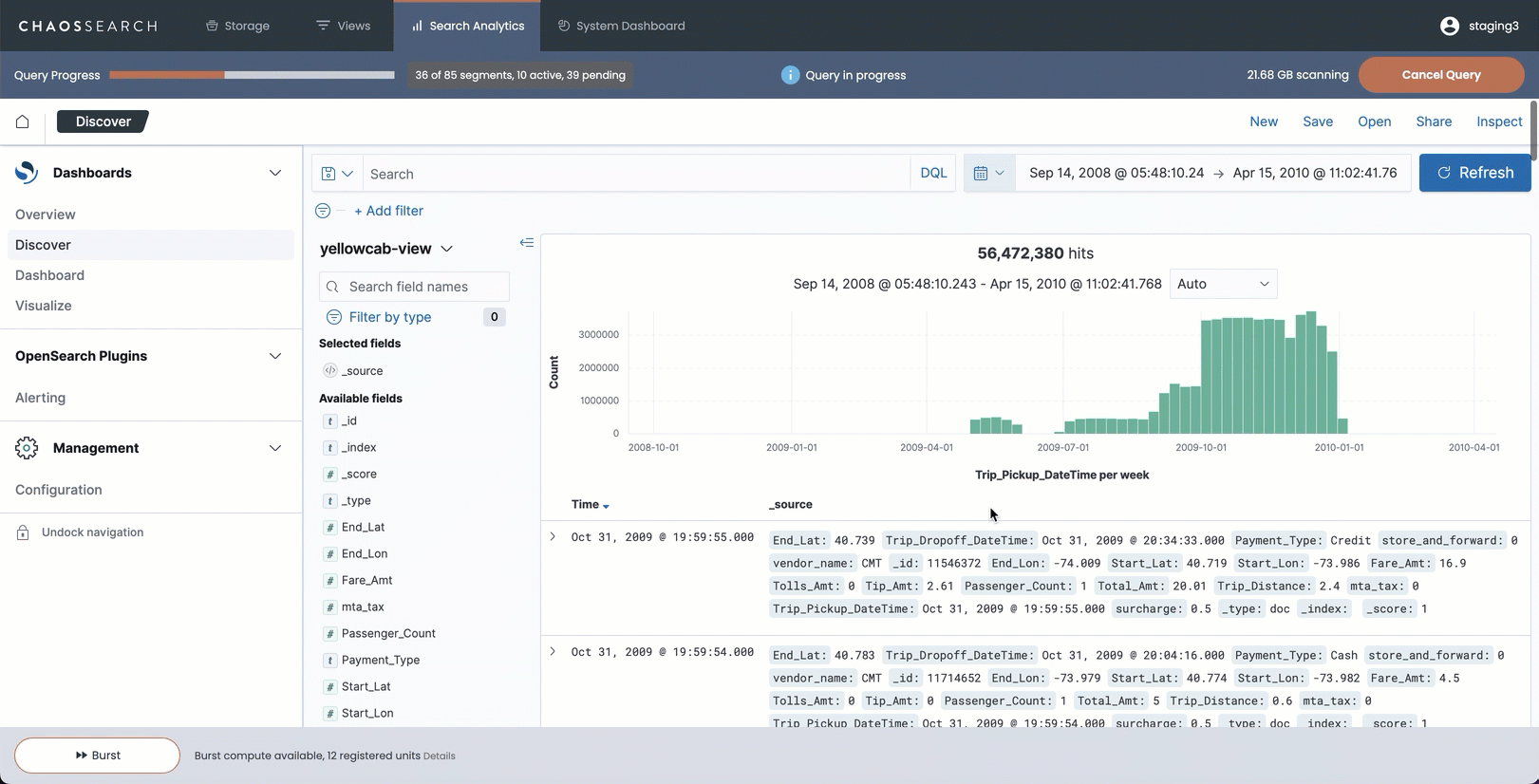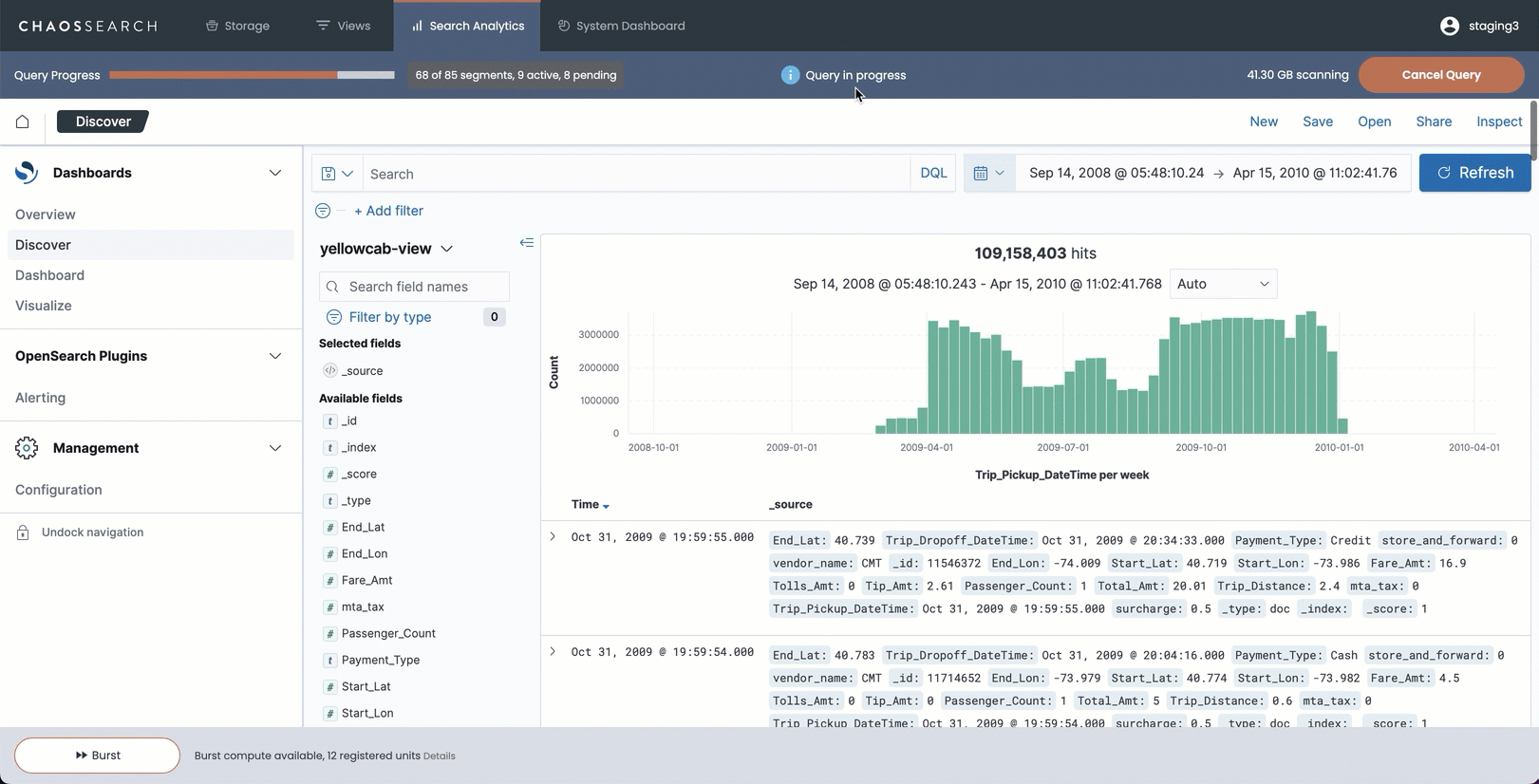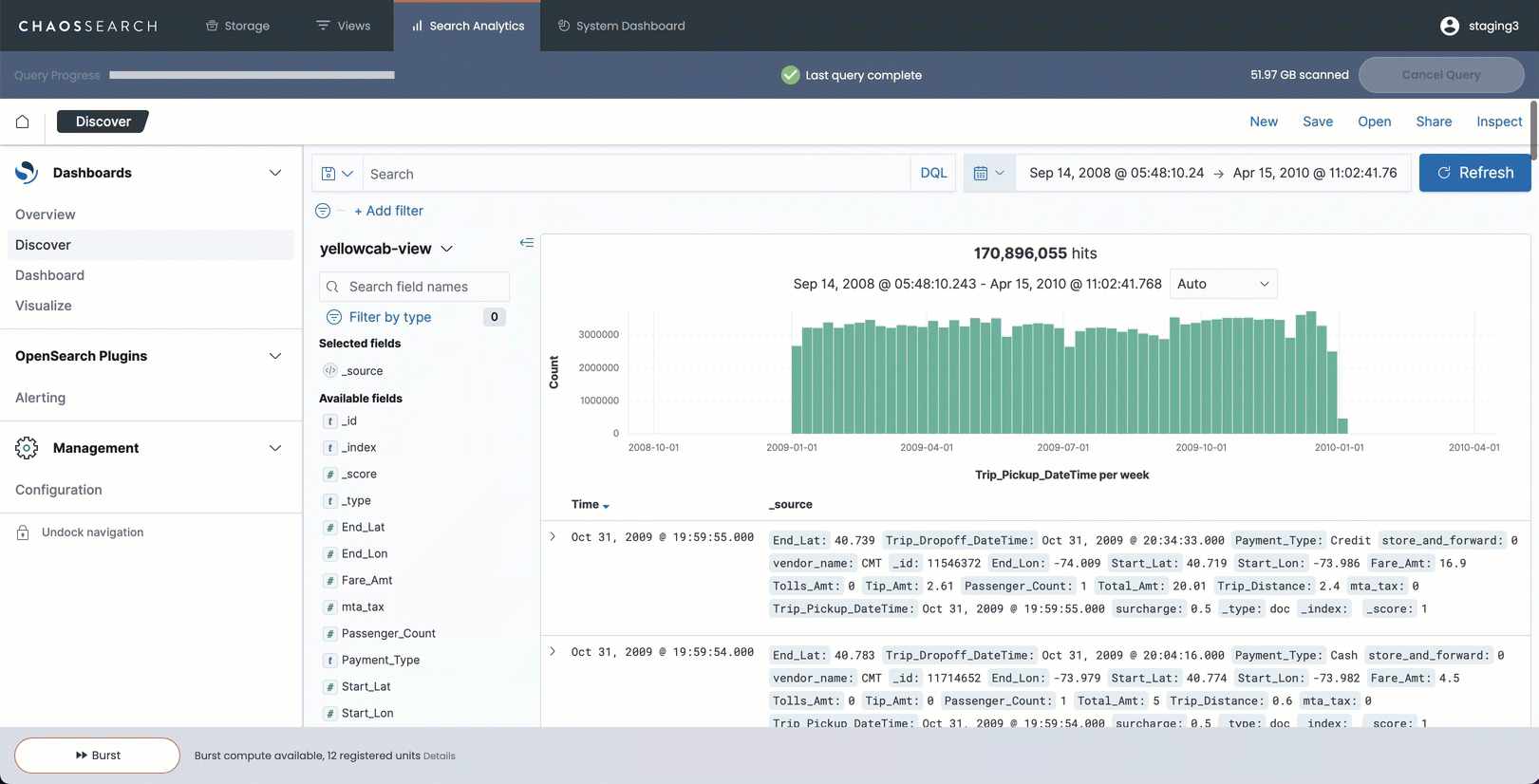
For smaller searches when only a few segments are scanned, users typically do not see incremental results; all the results are returned to the histogram in one response.
Incremental Results Mechanism
The incremental results feature is implemented using the /kibana/internal/_msearch endpoint. TheCookie parameter incrementalQuerying=true must be added to the Headers of the endpoint to enable incremental results support.
When enabled, the system issues periodic /kibana/internal/_msearch requests while the search runs. While a smaller scale search might have only one _msearch call, longer searches could have many _msearch calls, until the search is finished.
Within the second and subsequent _msearch requests (up to the last one), the Response payload of the endpoint includes a streaming_result_id field with the unique query UUID value to indicate that the message contains a portion of the results for this query (e.g., "streaming_result_id": "d75b665c-a51d-4fff-9247-dd40f6f4d49b" at the end of the "body" field).
The last _msearch (when the query is complete) does not show thestreaming_result_id field in the Response payload.
Incremental Loading in ElasticSearch APIs
When using programmatic ElasticSearch APIs, you can use the /kibana/internal/_msearch endpoint and the incrementalQuerying=true Headers Cookie value in the API call to run in incremental results mode.
Sample Python Script for Incremental Load
The following python script is a sample search that matches on all records in my-sample-view and uses the incremental results loading feature. The results/hits are written to a sample log file incremental-api.log.
There is a version of the script that uses a JWT for authentication, and one that uses a ChaosSearch API Key for authentication.
import argparse
import json
import logging
import requests
from requests_aws4auth import AWS4Auth
es_url, host, access_key, secret_key, account, region = "", "", "", "", "", ""
es_payload = {"searches": [{
"header": {"index": "my-sample-view", "preference": 1722883631615},
"body": {
"query": {
"bool": {
"must": [],
"filter": [
{
"match_all": {}
},
{
"range": {
"timestamp": {
"gte": "2018-08-01T00:00:00.000Z",
"lte": "2024-08-06T00:00:00.000Z",
"format": "strict_date_optional_time"
}
}
}
],
"should": [],
"must_not": []
}
}
}
}]}
def parse_args():
parser = argparse.ArgumentParser(description='Concurrency')
parser.add_argument('--access_key', required=True, help='The API access key')
parser.add_argument('--secret_key', required=True, help='The API secret key')
parser.add_argument('--region', required=True, help='The AWS region')
parser.add_argument('--host', required=True, help='The hostname')
parser.add_argument('--account', required=True, help='The CS account id')
return parser.parse_args()
def make_es_request(streaming_result_id=None):
awsauth = AWS4Auth(access_key, secret_key, region, 's3')
es_headers = {
"Accept": "*/*",
"Content-Type": "application/json",
}
cookies = {
"incrementalQuerying": "true",
"chaossumo_route_token": account,
"streaming_result_id": streaming_result_id
}
logging.info(f"Posting request {es_url}")
response = requests.request("POST", es_url, auth=awsauth, json=es_payload, headers=es_headers, cookies=cookies, verify=True, allow_redirects=True)
logging.info(f"Response code: {response.status_code}")
logging.info(f"Response text: {response.text}")
es_response_json = json.loads(response.text)
logging.info(f"Response json: {es_response_json}")
if response.status_code != 200:
logging.info("Request failed %s", es_response_json)
raise Exception("non-200 es response code")
else:
logging.info("Successful request")
logging.info(es_response_json)
if not "streaming_result_id" in es_response_json["body"]:
logging.info("Query complete")
hits = es_response_json["body"]["responses"][0]["hits"]["hits"]
x = 0
for hit in hits:
logging.info(f"hit: {hit}")
x += 1
return json.loads(response.text)
else:
total = es_response_json["body"]["responses"][0]["hits"]["total"]
logging.info(f"Incremental response received: {total} hits")
return make_es_request(es_response_json["body"]["streaming_result_id"])
def main():
logging.info("Main: Start")
args = parse_args()
global host
global access_key
global secret_key
global account
global region
global es_url
host = args.host
account = args.account
access_key = args.access_key
secret_key = args.secret_key
region = args.region
es_url = "https://" + host + "/kibana/internal/_msearch"
resp_text = make_es_request()
logging.info(f"Response: {resp_text}")
logging.info("Main: End")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO, filename='incremental-api.log')
main()import argparse
import json
import logging
import requests
from lowercase_booleans import true
view = "my-sample-view"
bucket = ""
token_url = ""
token_headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"x-amz-chaossumo-route-token": "login"
}
token_payload = {}
es_url = ""
es_payload = {"searches": [{
"header": {"index": "my-sample-view", "preference": 1722883631615},
"body": {
"query": {
"bool": {
"must": [],
"filter": [
{
"match_all": {}
},
{
"range": {
"timestamp": {
"gte": "2024-08-01T00:00:00.000Z",
"lte": "2024-08-06T00:00:00.000Z",
"format": "strict_date_optional_time"
}
}
}
],
"should": [],
"must_not": []
}
}
}
}]}
def parse_args():
parser = argparse.ArgumentParser(description='Concurrency')
parser.add_argument('--cs_user', required=True, help='The CS user id')
parser.add_argument('--cs_pwd', required=True, help='The CS user password')
parser.add_argument('--host', required=True, help='The hostname')
parser.add_argument('--account', required=True, help='The CS account id')
return parser.parse_args()
def get_token():
response = requests.request("POST", token_url, json=token_payload, headers=token_headers, verify=True)
logging.info("Token request response %s", response)
if response.status_code != 200:
logging.info("Request failed to retrieve token")
raise Exception("non-200 token response code")
else:
logging.info("Successfully retrieved token")
return json.loads(response.text)['Token']
def make_es_request(streaming_result_id=None):
token = get_token()
es_headers = {
"Accept": "*/*",
"Content-Type": "application/json",
}
cookies = {
"incrementalQuerying": "true",
"chaossumo_route_token": account,
"chaossumo_session_token": token,
"streaming_result_id": streaming_result_id
}
logging.info(f"Posting request {es_url}")
response = requests.request("POST", es_url, json=es_payload, headers=es_headers, cookies=cookies, verify=True, allow_redirects=True)
logging.info(f"Response code: {response.status_code}")
logging.info(f"Response text: {response.text}")
es_response_json = json.loads(response.text)
logging.info(f"Response json: {es_response_json}")
if response.status_code != 200:
logging.info("Request failed %s", es_response_json)
raise Exception("non-200 es response code")
else:
logging.info("Successful request")
logging.info(es_response_json)
if not "streaming_result_id" in es_response_json["body"]:
logging.info("Query complete")
hits = es_response_json["body"]["responses"][0]["hits"]["hits"]
x = 0
for hit in hits:
#print(hit)
logging.info(f"hit: {hit}")
x += 1
#print(x)
return json.loads(response.text)
else:
total = es_response_json["body"]["responses"][0]["hits"]["total"]
logging.info(f"Incremental response received: {total} hits")
return make_es_request(es_response_json["body"]["streaming_result_id"])
def main():
logging.info("Main: Start")
args = parse_args()
global host
global token_url
global token_payload
global account
global es_url
host = args.host
account = args.account
token_url = "https://" + host + "/User/login"
token_payload = {"Username": args.cs_user, "Password": args.cs_pwd,
"ParentUid": account, "Type": "service", "UniqueSession": true}
es_url = "https://" + host + "/kibana/internal/_msearch"
resp_text = make_es_request()
logging.info(f"Response: {resp_text}")
logging.info("Main: End")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO, filename='incremental-api.log')
main()
In the sample python script, update the my-sample-view name and _msearch query parameters as applicable for your search. (The preference value is required, but not used at present. Specify any integer value.)
Run the API Keys version of the script with a python command similar to the following:
python incremental-api.py --access_key <cs_api_key> --secret_key <secret> --region <region> --host <cs_host> --account \<cs_external_uuid>
Run the JWT script with a python command similar to the following:
python incremental-api.py --cs_user <cs_user> --cs_pwd <cs_password> --host <cs_host> --account <cs_external_uuid>
The script might require a few minutes to complete.
This feature is available for embedded analytics customers on worker-based pricing.Contact your ChaosSearch Customer Success representative for more information about this feature.
Updated about 1 year ago