Creating a View for Isolated Data
Define views with isolation keys to filter analysis and results to only the segments of data that users need to see.
If you created object groups that use isolation keys (formerly called partition keys) to separate the indexed data for the group, the views that you create can use those isolation keys to filter the data visibility and results to one or more isolation keys. Scoping the view with isolation keys also offers a performance advantage for the users who query within specific isolation slices, by eliminating work for the data associated with all other isolation slices.
To create a view with an isolation key visibility rule:
- Follow the standard instructions to create a view. Go to Views and then click Create View.
- Select the object group in the left frame, then click Next.

In the Schema Transformation window, scroll to the column that is used for the partition key (this example uses the default cs_partition_key_0 column) and click the filter icon on the right.
NOTE: Your partition key column could vary.The
cs_partition_key_#column is created by ChaosSearch during indexing when an object group is configured with an isolation key rule. If your isolation key regex used a named capture group to specify a unique name for your key column, use your designated column in this procedure to filter the data to be analyzed by this view.In some cases, the isolation key values could also be identical to values for another field of the object group. For example, if you create isolation keys based on AWS cloud region values, and your indexed data also has an
aws_regionfield with identical key value strings, you could use the more familiaraws_regioncolumn as the isolation key filter for the view. See Using an Alternate View Column as the Isolation Key later in this topic.
- The Configure Filter window opens. You can specify an isolation key by using one of the following two methods. You can repeat the steps to select more than one isolation key for a view.
- Type an isolation value defined in the object group into the Insert Filter field and click Create.

- Select Use isolation keys and the system displays a list of the available isolation keys. Select a key that you want to use for the view, and then click Create to save the setting.
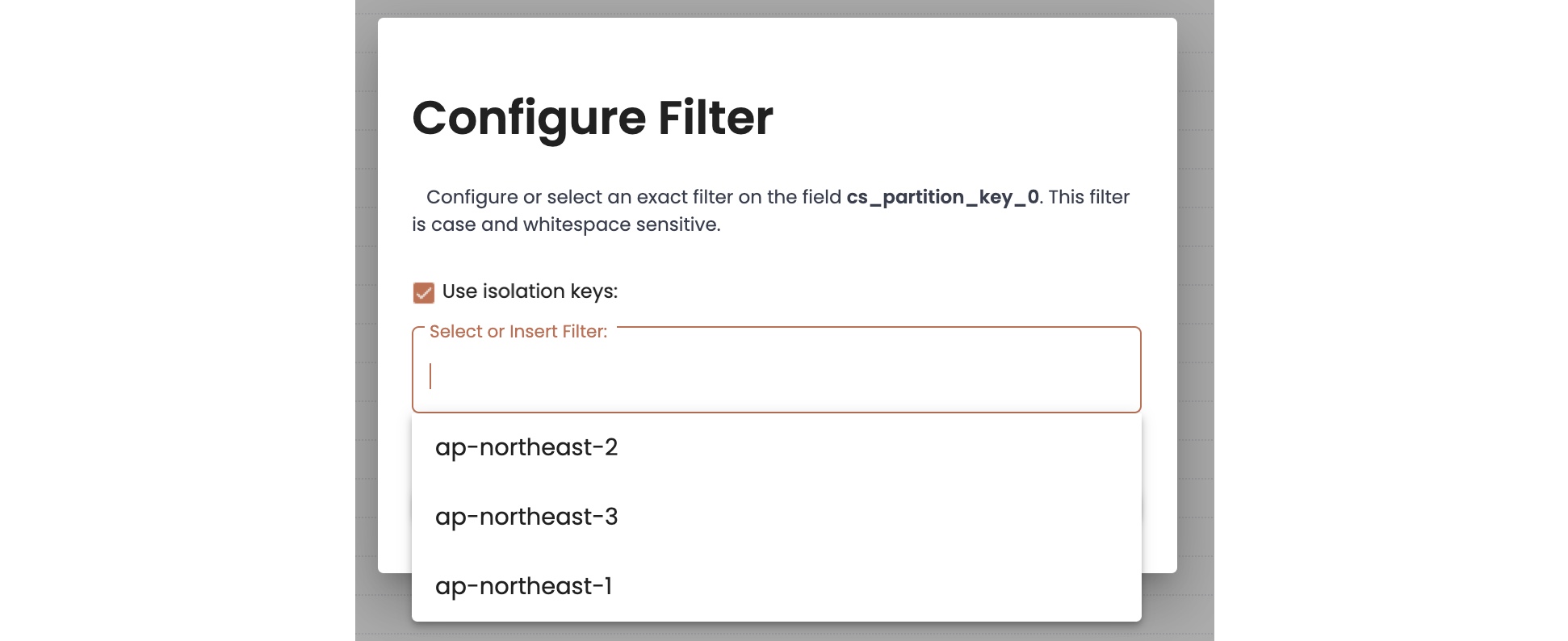
- The Schema Transformation window updates to show the selected isolation key value(s) for the
ca_partition_key_0field, as in the following example:

- Click Save Transform in the top right to save and close the window.
- Click Next in the Schema Transformation window and complete the view creation using the standard steps.
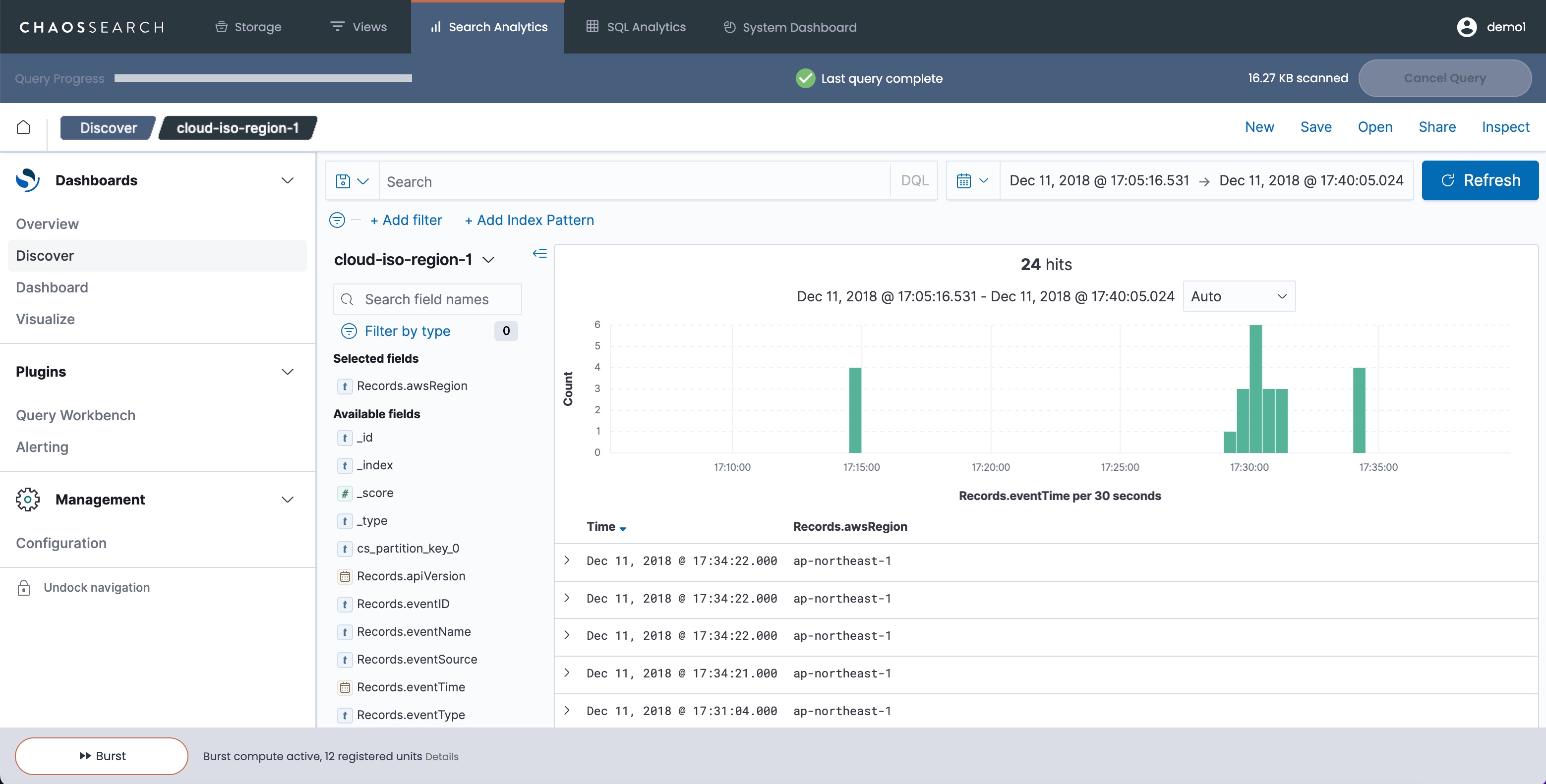
Users who have access to the view see only the indexed data related to the isolation key(s) that you specified. A sample Search Analytics > Discover window for a view that shows the ap-northeast-1 data follows:
Using an Alternate View Column as the Isolation Key
In most cases you use the cs_partition_key_# column, or your custom capture group field name(as described in Configuring Object Group Isolation Keys), to configure the isolation filtering for the views, as shown in the steps earlier in this topic.
However, if your indexed data has a column that contains the identical isolation key values, you could—as an alternative—use the more familiar column to configure the view data visibility. Sometimes the alternative column might have a more meaningful and recognizable name, and be easier to use for filtering and configuration.
For example, the object group in this example has isolation keys that are based on region values like ap-northeast-1 and ap-northeast-2 and so on. In this example, the same isolation key values are also stored in the Records.awsRegion column. If Records.awsRegion is a more familiar column for your users, you can follow almost the same steps to configure your isolation rules using Records.awsRegion.
To use an alternate column for configuring isolation in a view:
- When you create the view, in the Schema Transformation window, scroll to the alternate column that you want to use, such as
Records.awsRegion, and click the gear (Transform) icon on the right. The Schema Transformation window opens.
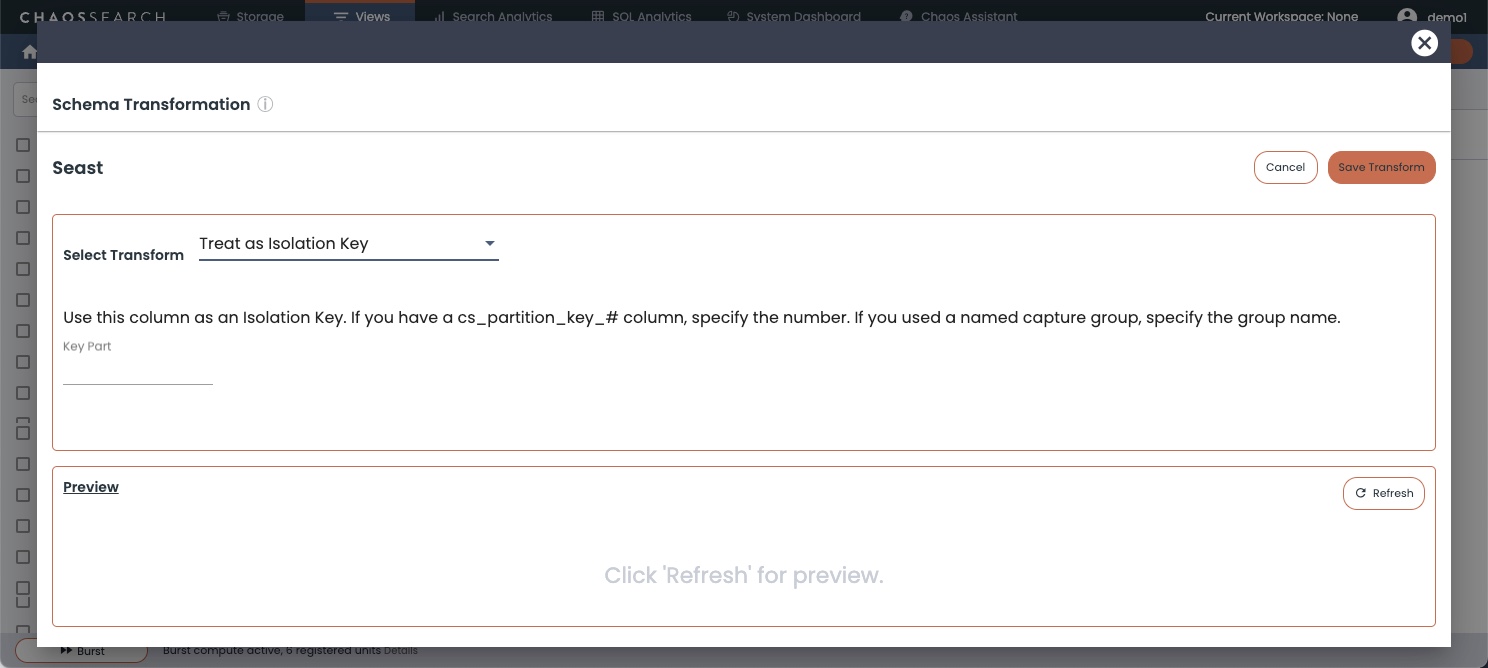
2.Click the Select Transformation list.
- Select the Treat as Isolation Key option to configure this column as an isolation key column.
- Optionally, if prompted, verify that
0is the correct number at the end of yourcs_partition_key_#field. It is most likely 0, but it could be a different number in some cases. If you are using a named capture group, specify the capture group name for the key part. - Click Save Transform. The Schema Transformation window closes and the main Schema Transformation window appears.
- Click the filter icon for your column (
Records.awsRegion), to open the Filter window. Notice that the Filter window is forRecords.awsRegion, and the drop-down list includes the same isolation key values as incs_partition_key_#. (If the values of this column do not match the keys used incs_partition_key_#or the named capture group, the alternate column will not work for isolation.)

- Select the one or more isolation key values, as in the earlier steps, to specify the isolation key(s) to use for this view, and click Create.
The Schema Transformation window updates to show the configuration for the Records.awsRegion column to be treated as an isolation key, and the filter for the ap-northeast-1 keys.

- Click Next and complete the steps to save the view.
In this example, the view is limited to only the indexed data associated with the specified ap-northeast-1 key selected for the Records.awsRegion column. This configuration is identical to the effect using the cs_partition_key_0 field.
Updated about 1 year ago