Isolation Key Overview
An overview of isolation key-based object groups and their benefits
One object group can filter and index all source objects in a cloud storage bucket that have the same format and compression and that use the same index rules. You can create multiple object groups to index different collections of source files, but it is a good practice to use the fewest number of live object groups as possible for the compute savings.
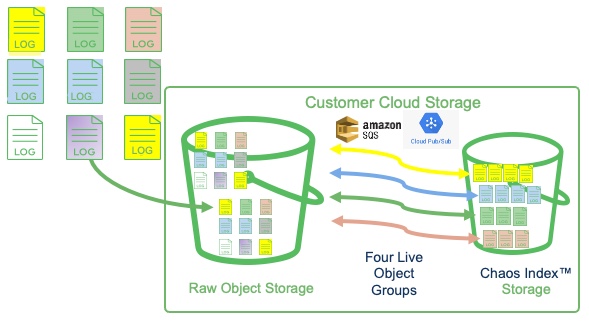
If the format, compression, and indexing rules are the same for a collection of object store files, it is more efficient to use one live object group to do the work of multiple object groups. The isolation key feature can keep the index data segregated in slices for data isolation and visibility/analysis needs.
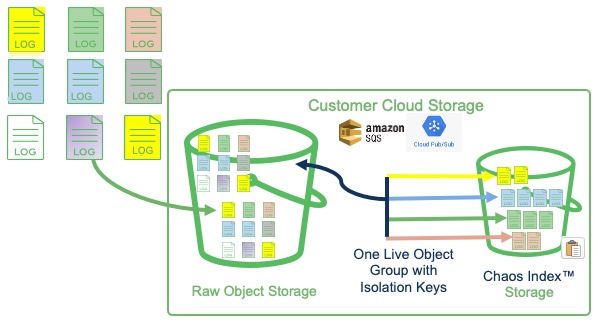
Carefully plan the regular expressions for the object group filter and for the isolation key rule to ensure that you have a good storage object file match for the overall group, and that the isolation key expression creates the correct separations that will be used as filters by the Refinery views (created later).
Updated about 1 year ago